BERT, skratka pre reprezentácie obojsmerného kódovača od spoločnosti Transformers , stojí ako open-source rámec strojového učenia určené pre oblasť spracovanie prirodzeného jazyka (NLP) . Tento rámec, ktorý vznikol v roku 2018, vytvorili výskumníci z Google AI Language. Cieľom článku je preskúmať architektúra, fungovanie a aplikácie BERT .
čo je BERT?
BERT (obojsmerné reprezentácie kódovača od spoločnosti Transformers) využíva neurónovú sieť založenú na transformátore na pochopenie a generovanie ľudského jazyka. BERT používa architektúru iba s kódovačom. V origináli Architektúra transformátora , existujú moduly kódovania aj dekódovania. Rozhodnutie použiť v BERT architektúru len s kódovačom naznačuje primárny dôraz na pochopenie vstupných sekvencií a nie na generovanie výstupných sekvencií.
Obojsmerný prístup BERT
Tradičné jazykové modely spracovávajú text postupne, buď zľava doprava alebo sprava doľava. Táto metóda obmedzuje povedomie modelu na bezprostredný kontext predchádzajúci cieľovému slovu. BERT používa obojsmerný prístup, pričom berie do úvahy ľavý aj pravý kontext slov vo vete, namiesto toho, aby analyzoval text postupne, BERT sa pozerá na všetky slová vo vete súčasne.
Príklad: Breh sa nachádza na _______ rieky.
V jednosmernom modeli by porozumenie blanku do značnej miery záviselo od predchádzajúcich slov a model by mohol mať problém rozlíšiť, či banka odkazuje na finančnú inštitúciu alebo na breh rieky.
BERT, keďže je obojsmerný, súčasne zohľadňuje ľavý (breh sa nachádza na) aj pravý kontext (rieky), čo umožňuje jemnejšie pochopenie. Chápe, že chýbajúce slovo pravdepodobne súvisí s geografickou polohou banky, čo dokazuje kontextové bohatstvo, ktoré obojsmerný prístup prináša.
Predtréning a dolaďovanie
Model BERT prechádza dvojstupňovým procesom:
- Predškolenie na veľké množstvo neoznačeného textu na naučenie sa kontextového vloženia.
- Jemné doladenie označených údajov pre konkrétne NLP úlohy.
Predškolenie o veľkých dátach
- BERT je vopred trénovaný na veľké množstvo neoznačených textových údajov. Model sa učí kontextové vloženia, čo sú reprezentácie slov, ktoré berú do úvahy ich okolitý kontext vo vete.
- BERT sa zapája do rôznych predtréningových úloh bez dozoru. Napríklad sa môže naučiť predpovedať chýbajúce slová vo vete (Masked Language Model alebo MLM úloha), pochopiť vzťah medzi dvoma vetami alebo predpovedať nasledujúcu vetu v páre.
Jemné doladenie označených údajov
- Po predtréningovej fáze je model BERT, vyzbrojený svojimi kontextovými vložkami, doladený pre špecifické úlohy spracovania prirodzeného jazyka (NLP). Tento krok prispôsobuje model pre cielenejšie aplikácie prispôsobením jeho všeobecného jazykového porozumenia nuansám konkrétnej úlohy.
- BERT je doladený pomocou označených údajov špecifických pre nadväzujúce úlohy, ktoré sú predmetom záujmu. Tieto úlohy môžu zahŕňať analýzu sentimentu, odpovedanie na otázky, rozpoznanie pomenovanej entity alebo akejkoľvek inej aplikácie NLP. Parametre modelu sú upravené tak, aby optimalizovali jeho výkon pre konkrétne požiadavky danej úlohy.
Jednotná architektúra BERT mu umožňuje prispôsobiť sa rôznym následným úlohám s minimálnymi úpravami, čo z neho robí všestranný a vysoko efektívny nástroj v porozumenie prirodzenému jazyku a spracovanie.
Ako funguje BERT?
BERT je navrhnutý tak, aby generoval jazykový model, takže sa používa iba mechanizmus kódovania. Postupnosť tokenov sa privádza do kódovača Transformer. Tieto tokeny sú najskôr vložené do vektorov a následne spracované v neurónovej sieti. Výstupom je sekvencia vektorov, z ktorých každý zodpovedá vstupnému tokenu a poskytuje kontextové reprezentácie.
Pri trénovaní jazykových modelov je definovanie cieľa predikcie výzvou. Mnoho modelov predpovedá ďalšie slovo v sekvencii, čo je smerový prístup a môže obmedziť kontextové učenie. BERT rieši túto výzvu dvoma inovatívnymi tréningovými stratégiami:
- Maskovaný jazykový model (MLM)
- Predpoveď ďalšej vety (NSP)
1. Maskovaný jazykový model (MLM)
V procese predbežného školenia BERT je časť slov v každej vstupnej sekvencii maskovaná a model je trénovaný tak, aby predpovedal pôvodné hodnoty týchto maskovaných slov na základe kontextu, ktorý poskytujú okolité slová.
Zjednodušene povedané,
- Maskovanie slov: Predtým, ako sa BERT naučí z viet, skryje niektoré slová (asi 15 %) a nahradí ich špeciálnym symbolom, napríklad [MASK].
- Hádanie skrytých slov: Úlohou BERT je zistiť, čo sú tieto skryté slová tým, že sa pozrieme na slová okolo nich. Je to ako hra v hádaní, kde niektoré slová chýbajú, a BERT sa snaží vyplniť prázdne miesta.
- Ako sa BERT učí:
- BERT pridáva špeciálnu vrstvu na vrchol svojho vzdelávacieho systému, aby mohol robiť tieto odhady. Potom skontroluje, ako blízko sú jeho odhady skutočným skrytým slovám.
- Robí to tak, že svoje odhady prevádza na pravdepodobnosti a hovorí: Myslím, že toto slovo je X a som si tým istý.
- Zvláštna pozornosť skrytým slovám
- BERT sa počas tréningu zameriava hlavne na to, aby tieto skryté slová boli správne. Menej sa stará o predpovedanie slov, ktoré nie sú skryté.
- Je to preto, že skutočnou výzvou je zistiť chýbajúce časti a táto stratégia pomáha spoločnosti BERT stať sa skutočne dobrým v chápaní významu a kontextu slov.
Z technického hľadiska
- BERT pridáva klasifikačnú vrstvu nad výstup z kódovača. Táto vrstva je rozhodujúca pre predpovedanie maskovaných slov.
- Výstupné vektory z klasifikačnej vrstvy sa vynásobia maticou vkladania a transformujú sa do dimenzie slovnej zásoby. Tento krok pomáha zosúladiť predpovedané reprezentácie s priestorom slovnej zásoby.
- Pravdepodobnosť každého slova v slovnej zásobe sa vypočíta pomocou Aktivačná funkcia SoftMax . Tento krok generuje rozdelenie pravdepodobnosti v rámci celej slovnej zásoby pre každú maskovanú pozíciu.
- Stratová funkcia používaná počas tréningu zohľadňuje iba predikciu maskovaných hodnôt. Model je penalizovaný za odchýlku medzi jeho predpoveďami a skutočnými hodnotami maskovaných slov.
- Model konverguje pomalšie ako smerové modely. Je to preto, že počas tréningu sa BERT zaoberá iba predpovedaním maskovaných hodnôt, pričom ignoruje predikciu nezamaskovaných slov. Zvýšené povedomie o kontexte dosiahnuté prostredníctvom tejto stratégie kompenzuje pomalšiu konvergenciu.
2. Predpoveď ďalšej vety (NSP)
BERT predpovedá, či je druhá veta spojená s prvou. Robí sa to transformáciou výstupu tokenu [CLS] na vektor v tvare 2×1 pomocou klasifikačnej vrstvy a následným výpočtom pravdepodobnosti, či druhá veta nasleduje po prvej, pomocou SoftMax.
- V tréningovom procese sa BERT učí chápať vzťah medzi pármi viet a predpovedať, či druhá veta nasleduje za prvou v pôvodnom dokumente.
- 50 % vstupných párov má druhú vetu ako nasledujúcu vetu v pôvodnom dokumente a ďalších 50 % má náhodne vybranú vetu.
- Pomôcť modelu rozlišovať medzi spojenými a nesúvisiacimi vetnými pármi. Vstup sa spracuje pred vstupom do modelu:
- Token [CLS] sa vloží na začiatok prvej vety a token [SEP] sa pridá na koniec každej vety.
- Ku každému tokenu sa pridá vloženie vety označujúce vetu A alebo vetu B.
- Polohové vloženie označuje pozíciu každého tokenu v sekvencii.
- BERT predpovedá, či je druhá veta spojená s prvou. Robí sa to transformáciou výstupu tokenu [CLS] na vektor v tvare 2×1 pomocou klasifikačnej vrstvy a následným výpočtom pravdepodobnosti, či druhá veta nasleduje po prvej, pomocou SoftMax.
Počas tréningu modelu BERT sa Masked LM a Next Sentence Prediction trénujú spoločne. Cieľom modelu je minimalizovať kombinovanú stratovú funkciu Masked LM a Next Sentence Prediction, čo vedie k robustnému jazykovému modelu s vylepšenými schopnosťami porozumieť kontextu viet a vzťahom medzi vetami.
Prečo trénovať Masked LM a Next Sentence Prediction spolu?
Maskovaný LM pomáha BERT pochopiť kontext vo vete a Predpoveď ďalšej vety pomáha BERT pochopiť spojenie alebo vzťah medzi pármi viet. Spoločné trénovanie oboch stratégií teda zaisťuje, že BERT sa naučí širokému a komplexnému porozumeniu jazyka a zachytí tak detaily vo vetách, ako aj tok medzi vetami.
Architektúra BERT
Architektúra BERT je viacvrstvový obojsmerný transformátorový kódovač, ktorý je celkom podobný modelu transformátora. Architektúra transformátora je sieť kódovač-dekodér, ktorá používa sebapozornosť na strane kodéra a pozornosť na strane dekodéra.
- BERTBASEmá 1 2 vrstvy v zásobníku kódovača zatiaľ čo BERTVEĽKÝmá 24 vrstiev v zásobníku kódovača . Ide o viac ako len o architektúru Transformera opísanú v pôvodnom článku ( 6 vrstiev kódovača ).
- Architektúry BERT (BASE a LARGE) majú tiež väčšie dopredné siete (768 resp. 1024 skrytých jednotiek) a viac hláv pozornosti (12 a 16 v tomto poradí) než architektúra Transformer navrhovala v pôvodnom článku. Obsahuje 512 skrytých jednotiek a 8 hláv pozornosti .
- BERTBASEobsahuje 110 miliónov parametrov, zatiaľ čo BERTVEĽKÝmá 340M parametrov.

Architektúra BERT BASE a BERT LARGE.
Tento model berie CLS token ako vstup, potom nasleduje sekvencia slov ako vstup. CLS je tu klasifikačný token. Potom odovzdá vstup do vyššie uvedených vrstiev. Platí každá vrstva sebapozornosť a výsledok odovzdá cez doprednú sieť, potom sa odovzdá ďalšiemu kódovaču. Výstupom modelu je vektor skrytej veľkosti ( 768 pre BERT BASE). Ak chceme výstup klasifikátora z tohto modelu, môžeme vziať výstup zodpovedajúci CLS tokenu.
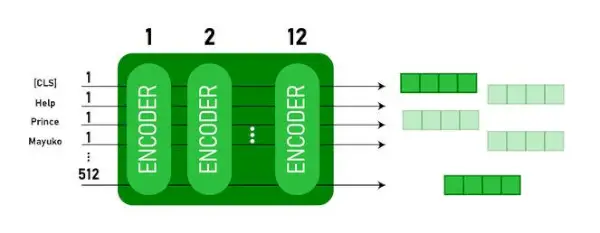
Výstup BERT ako vloženia
Teraz môže byť tento trénovaný vektor použitý na vykonávanie množstva úloh, ako je klasifikácia, preklad atď. Napríklad papier dosahuje skvelé výsledky len s použitím jednej vrstvy Neurónová sieť na modeli BERT v klasifikačnej úlohe.
Ako používať model BERT v NLP?
BERT možno použiť na rôzne úlohy spracovania prirodzeného jazyka (NLP), ako napríklad:
1. Klasifikačná úloha
- BERT možno použiť na klasifikačné úlohy, napr analýza sentimentu , cieľom je klasifikovať text do rôznych kategórií (pozitívny/negatívny/neutrálny), BERT možno použiť pridaním klasifikačnej vrstvy na vrch výstupu Transformera pre token [CLS].
- Token [CLS] predstavuje súhrnné informácie z celej vstupnej sekvencie. Táto združená reprezentácia sa potom môže použiť ako vstup pre klasifikačnú vrstvu na vytváranie predpovedí pre konkrétnu úlohu.
2. Zodpovedanie otázok
- Pri úlohách s odpovedaním na otázky, kde sa vyžaduje, aby model našiel a označil odpoveď v rámci danej textovej sekvencie, môže byť na tento účel vyškolený BERT.
- BERT je trénovaný na zodpovedanie otázok učením sa dvoch ďalších vektorov, ktoré označujú začiatok a koniec odpovede. Počas tréningu je model vybavený otázkami a zodpovedajúcimi pasážami a učí sa predpovedať počiatočnú a koncovú pozíciu odpovede v rámci pasáže.
3. Rozpoznanie pomenovanej entity (NER)
- BERT možno použiť pre NER, kde cieľom je identifikovať a klasifikovať entity (napr. osoba, organizácia, dátum) v textovej sekvencii.
- Model NER založený na BERT je trénovaný tak, že sa zoberie výstupný vektor každého tokenu z transformátora a vloží sa do klasifikačnej vrstvy. Vrstva predpovedá menovku pomenovanej entity pre každý token, pričom označuje typ entity, ktorú predstavuje.
Ako tokenizovať a kódovať text pomocou BERT?
Na tokenizáciu a kódovanie textu pomocou BERT budeme používať knižnicu „transformátor“ v Pythone.
Príkaz na inštaláciu transformátorov:
!pip install transformers>
- Načítame predtrénovaný tokenizér BERT s použitím slovnej zásoby v puzdre BertTokenizer.from_pretrained(bert-base-case) .
- tokenizer.encode(text) tokenizuje vstupný text a konvertuje ho na sekvenciu ID tokenov.
- print (ID tokenov:, kódovanie) vytlačí ID tokenov získané po kódovaní.
- tokenizer.convert_ids_to_tokens(kódovanie) konvertuje ID tokenov späť na ich zodpovedajúce tokeny.
- print(Tokens:, tokens) vytlačí tokeny získané po konverzii ID tokenov
Python3
from> transformers>import> BertTokenizer> # Load pre-trained BERT tokenizer> tokenizer>=> BertTokenizer.from_pretrained(>'bert-base-cased'>)> # Input text> text>=> 'ChatGPT is a language model developed by OpenAI, based on the GPT (Generative Pre-trained Transformer) architecture. '> # Tokenize and encode the text> encoding>=> tokenizer.encode(text)> # Print the token IDs> print>(>'Token IDs:'>, encoding)> # Convert token IDs back to tokens> tokens>=> tokenizer.convert_ids_to_tokens(encoding)> # Print the corresponding tokens> print>(>'Tokens:'>, tokens)> |
>
>
Výkon:
Token IDs: [101, 24705, 1204, 17095, 1942, 1110, 170, 1846, 2235, 1872, 1118, 3353, 1592, 2240, 117, 1359, 1113, 1103, 15175, 1942, 113, 9066, 15306, 11689, 118, 3972, 13809, 23763, 114, 4220, 119, 102] Tokens: ['[CLS]', 'Cha', '##t', '##GP', '##T', 'is', 'a', 'language', 'model', 'developed', 'by', 'Open', '##A', '##I', ',', 'based', 'on', 'the', 'GP', '##T', '(', 'Gene', '##rative', 'Pre', '-', 'trained', 'Trans', '##former', ')', 'architecture', '.', '[SEP]']> The tokenizer.encode metóda pridáva špeciálne [CLS] – klasifikácia a [SEP] – oddeľovač tokeny na začiatku a na konci kódovanej sekvencie.
Aplikácia BERT
BERT sa používa na:
- Textová reprezentácia: BERT sa používa na generovanie vloženia slov alebo reprezentácie slov vo vete.
- Rozpoznávanie pomenovanej entity (NER) : BERT možno doladiť pre úlohy rozpoznávania pomenovaných entít, kde cieľom je identifikovať entity, ako sú mená ľudí, organizácií, miest atď., v danom texte.
- Klasifikácia textu: BERT sa široko používa na úlohy klasifikácie textu vrátane analýzy sentimentu, detekcie spamu a kategorizácie tém. Preukázal vynikajúci výkon pri porozumení a klasifikácii kontextu textových údajov.
- Systémy odpovedania na otázky: BERT bol aplikovaný na systémy odpovedania na otázky, kde je model trénovaný na pochopenie kontextu otázky a poskytnutie relevantných odpovedí. To je užitočné najmä pri úlohách, ako je čítanie s porozumením.
- Strojový preklad: Kontextové vloženia BERT možno využiť na zlepšenie systémov strojového prekladu. Model zachytáva nuansy jazyka, ktoré sú kľúčové pre presný preklad.
- Zhrnutie textu: BERT možno použiť na abstraktnú sumarizáciu textov, kde model generuje stručné a zmysluplné zhrnutia dlhších textov pochopením kontextu a sémantiky.
- Konverzačná AI: BERT sa používa pri budovaní konverzačných systémov AI, ako sú chatboty, virtuálni asistenti a dialógové systémy. Jeho schopnosť pochopiť kontext ho robí efektívnym pre pochopenie a generovanie odpovedí prirodzeného jazyka.
- Sémantická podobnosť: Vloženie BERT možno použiť na meranie sémantickej podobnosti medzi vetami alebo dokumentmi. To je cenné pri úlohách, ako je detekcia duplikátov, identifikácia parafráz a vyhľadávanie informácií.
BERT vs GPT
Rozdiel medzi BERT a GPT je nasledovný:
| BERT | GPT | |
|---|---|---|
| Architektúra | BERT je navrhnutý pre obojsmerné učenie reprezentácie. Využíva cieľ maskovaného jazykového modelu, kde predpovedá chýbajúce slová vo vete na základe ľavého aj pravého kontextu. | GPT je na druhej strane určený na generatívne jazykové modelovanie. Predpovedá ďalšie slovo vo vete vzhľadom na predchádzajúci kontext, pričom využíva jednosmerný autoregresný prístup. |
| Predtréningové ciele | BERT je vopred vyškolený pomocou maskovaného jazykového modelu a predikcie ďalšej vety. Zameriava sa na zachytenie obojsmerného kontextu a pochopenie vzťahov medzi slovami vo vete. | GPT je vopred vyškolený na predpovedanie ďalšieho slova vo vete, čo podporuje model, aby sa naučil koherentnú reprezentáciu jazyka a generoval kontextovo relevantné sekvencie. |
| Porozumenie kontextu | BERT je účinný pri úlohách, ktoré si vyžadujú hlboké pochopenie kontextu a vzťahov vo vete, ako je klasifikácia textu, rozpoznávanie pomenovaných entít a odpovedanie na otázky. | Značka GPT je silná pri vytváraní súvislého a kontextovo relevantného textu. Často sa používa v kreatívnych úlohách, dialógových systémoch a úlohách vyžadujúcich generovanie sekvencií prirodzeného jazyka. |
| Typy úloh a prípady použitia
| Bežne sa používa v úlohách, ako je klasifikácia textu, rozpoznávanie pomenovaných entít, analýza sentimentu a odpovedanie na otázky. | Aplikuje sa na úlohy, ako je generovanie textu, dialógové systémy, sumarizácia a tvorivé písanie. |
| Jemné ladenie vs. Učenie s niekoľkými zábermi | BERT sa často dolaďuje na konkrétnych nadväzujúcich úlohách s označenými údajmi, aby prispôsobil svoje vopred natrénované reprezentácie danej úlohe. | GPT je navrhnutý tak, aby vykonával niekoľkonásobné učenie, kde sa môže zovšeobecniť na nové úlohy s minimálnymi údajmi o trénovaní špecifických pre danú úlohu. |
Skontrolujte tiež:
- Klasifikácia sentimentu pomocou BERT
- Ako vygenerovať vkladanie slov pomocou BERT?
- Model BART pre automatické dopĺňanie textu v NLP
- Klasifikácia toxických komentárov pomocou BERT
- Predikcia ďalšej vety pomocou BERT
Často kladené otázky (FAQ)
Otázka: Na čo sa BERT používa?
BERT sa používa na vykonávanie úloh NLP, ako je reprezentácia textu, rozpoznávanie pomenovaných entít, klasifikácia textu, systémy otázok a odpovedí, strojový preklad, sumarizácia textu a ďalšie.
Q. Aké sú výhody modelu BERT?
Jazykový model BERT vyniká rozsiahlym predškolením vo viacerých jazykoch a ponúka široké jazykové pokrytie v porovnaní s inými modelmi. Vďaka tomu je BERT obzvlášť výhodný pre projekty, ktoré nie sú založené na angličtine, pretože poskytuje robustné kontextové reprezentácie a sémantické porozumenie v rôznych jazykoch, čím sa zvyšuje jeho všestrannosť vo viacjazyčných aplikáciách.
Otázka: Ako funguje BERT pri analýze sentimentu?
BERT vyniká v analýze sentimentu tým, že využíva svoje učenie o obojsmernej reprezentácii na zachytenie kontextových nuancií, sémantických významov a syntaktických štruktúr v rámci daného textu. To umožňuje spoločnosti BERT pochopiť sentiment vyjadrený vo vete zvážením vzťahov medzi slovami, čo vedie k vysoko efektívnym výsledkom analýzy sentimentu.
aktualizácia z join sql
Otázka: Je Google založený na BERT?
BERT a RankBrain sú súčasti vyhľadávacieho algoritmu Google na spracovanie dopytov a obsahu webových stránok s cieľom lepšie pochopiť výsledky vyhľadávania.