Linuxový príkaz uniq sa používa na odstránenie všetkých opakovaných riadkov zo súboru. Môže sa tiež použiť na zobrazenie počtu ľubovoľných slov, iba opakovaných riadkov, ignorovanie znakov a porovnanie konkrétnych polí. Je to jeden z najčastejšie používaných príkazov v Linux systém. Často sa používa s príkaz na triedenie pretože porovnáva susedné znaky. Zahodí všetky rovnaké riadky a zapíše výstup.
Syntax:
uniq [OPTION]... [INPUT [OUTPUT]]
Možnosti:
Niektoré užitočné možnosti príkazového riadka príkazu uniq sú nasledovné:
-c, --count: predponuje riadky počtom výskytov.
-d, --opakované: používa sa na tlač duplicitných riadkov, jedného pre každú skupinu.
-D: Používa sa na tlač všetkých duplicitných riadkov.
--všetky-opakované[=METÓDA]: Je dosť podobná možnosti '-D', rozdiel medzi oboma možnosťami je v tom, že umožňuje oddelenie skupín prázdnym riadkom.
-f, --skip-fields=N: Používa sa, aby sa zabránilo porovnávaniu prvých N polí.
--skupina[=METÓDA]: Používa sa na zobrazenie všetkých položiek a oddeľuje skupiny prázdnym riadkom.
odstrániť prvý znak excel
-i, --ignore-case: Používa sa na ignorovanie rozdielov pri porovnávaní.
-s, --skip-chars=N: Používa sa, aby sa zabránilo porovnávaniu prvých N znakov.
-u, --jedinečné: používa sa na tlač jedinečných čiar.
-z, ---ukončené nulou: Používa sa, ak je oddeľovač riadkov NUL a nie režim nového riadku.
-w, --check-chars=N: Používa sa na porovnanie maximálne N znakov v riadkoch.
--Pomoc: Používa sa na zobrazenie dokumentácie pomocníka.
--verzia: Používa sa na zobrazenie informácií o verzii.
Príklady príkazu uniq
Pozrime sa na nasledujúce príklady príkazu uniq:
- Odstráňte opakované riadky
- spočítajte počet výskytov slova
- Zobrazte opakujúce sa riadky
- Zobrazte jedinečné čiary
- V porovnaní s tým ignorujte znaky
- Ignorovať polia v porovnaní
Odstráňte opakované riadky
Ak chcete odstrániť opakované riadky zo súboru, vykonajte základný príkaz uniq takto:
java tostring
sort dupli.txt | uniq
Vyššie uvedený príkaz odstráni duplicitné riadky zo súboru 'dupli.txt.' Zvážte nasledujúci výstup:
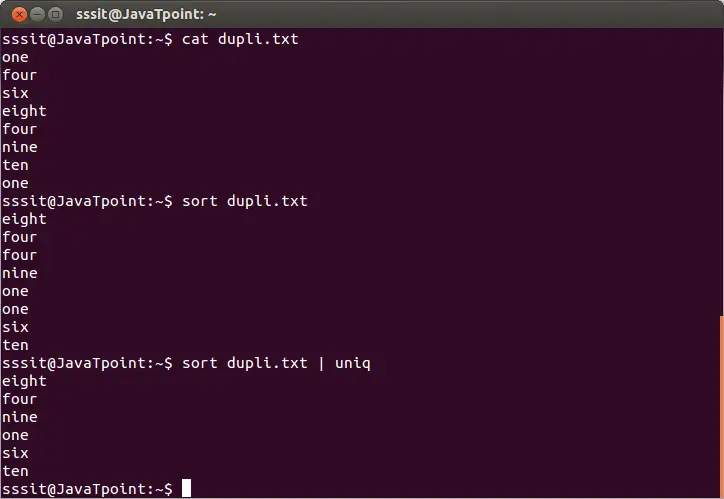
Z vyššie uvedeného výstupu sú opakujúce sa slová ignorované.
Spočítajte počet výskytov slova
Počet výskytov slova môžeme spočítať pomocou príkazu uniq. Možnosť '-c' sa používa na počítanie slova. Vykonajte to nasledovne:
sort dupli.txt | uniq -c
Vyššie uvedený príkaz spočíta slová, ktoré prichádzajú v 'dupli.txt'. Zvážte nasledujúci výstup:
ipconfig pre ubuntu

Z vyššie uvedeného výstupu príkaz 'sort dupli.txt | uniq -c' počíta, koľkokrát sa slovo opakuje.
Zobrazte opakujúce sa riadky
Voľba '-d' sa používa na zobrazenie iba opakujúcich sa riadkov. Zobrazí iba riadky, ktoré budú v súbore viackrát, a zapíše výstup na štandardný výstup. Zvážte nasledujúci príkaz:
sort dupli.txt | uniq -d
Vyššie uvedený príkaz zobrazí iba opakované riadky. Zvážte nasledujúci výstup:

Zobrazte jedinečné čiary
Voľba '-u' sa používa na zobrazenie iba jedinečných riadkov (ktoré sa neopakujú). Zobrazí iba riadky, ktoré sa vyskytujú iba raz, a zapíše výsledok na štandardný výstup. Zvážte nasledujúci príkaz:
sort dupli.txt | uniq -u
Vyššie uvedený príkaz zobrazí iba jedinečné riadky zo súboru 'dupli.txt'. Zvážte nasledujúci výstup:

V porovnaní s tým ignorujte znaky
Voľba '-s' sa používa na ignorovanie znakov v porovnaní. Ignoruje zadaný počet znakov a zobrazí výsledok na štandardný výstup. Zvážte nasledujúci príkaz:
sort dupli.txt | uniq -s 2
Vyššie uvedený príkaz bude ignorovať prvé dva znaky v porovnaní zo súboru 'dupli.txt'. Zvážte nasledujúci výstup:

Ignorovať polia v porovnaní
Voľba '-f' sa používa na ignorovanie polí. Zvážte nasledujúci príkaz:
uniq -f 2 dupli2.txt
Vyššie uvedený príkaz nebude porovnávať prvé dve polia zo súboru 'dupli2.txt'. Zvážte nasledujúci výstup:

Z vyššie uvedeného výstupu sa prvé dve polia preskočia a ostatné polia sa porovnajú zo súboru 'dupli2.txt'.