Jeden dôležitý aspekt Strojové učenie je hodnotenie modelu. Na vyhodnotenie vášho modelu musíte mať nejaký mechanizmus. Tu sa dostávajú do obrazu tieto výkonnostné metriky, ktoré nám dávajú predstavu o tom, aký dobrý je model. Ak ste oboznámení s niektorými základmi Strojové učenie potom ste sa museli stretnúť s niektorými z týchto metrík, ako je presnosť, presnosť, zapamätanie, auc-roc atď., ktoré sa všeobecne používajú na klasifikačné úlohy. V tomto článku do hĺbky preskúmame jednu takú metriku, ktorou je krivka AUC-ROC.
Obsah
- Čo je krivka AUC-ROC?
- Kľúčové pojmy používané v krivke AUC a ROC
- Vzťah medzi citlivosťou, špecifickosťou, FPR a prahom.
- Ako funguje AUC-ROC?
- Kedy by sme mali použiť hodnotiacu metriku AUC-ROC?
- Špekuluje sa o výkone modelu
- Pochopenie krivky AUC-ROC
- Implementácia pomocou dvoch rôznych modelov
- Ako použiť ROC-AUC pre viactriedny model?
- Časté otázky pre krivku AUC ROC v strojovom učení
Čo je krivka AUC-ROC?
Krivka AUC-ROC alebo krivka oblasti pod prevádzkovou charakteristikou prijímača je grafickým znázornením výkonu binárneho klasifikačného modelu pri rôznych klasifikačných prahoch. Bežne sa používa v strojovom učení na posúdenie schopnosti modelu rozlišovať medzi dvoma triedami, typicky pozitívnou triedou (napr. prítomnosť choroby) a negatívnou triedou (napr. neprítomnosť choroby).
Najprv pochopme význam týchto dvoch pojmov ROC a AUC .
- ROC : Prevádzkové charakteristiky prijímača
- AUC : Oblasť pod krivkou
Krivka prevádzkových charakteristík prijímača (ROC).
ROC je skratka pre Receiver Operating Characteristics a ROC krivka je grafickým znázornením účinnosti modelu binárnej klasifikácie. Vykresľuje mieru skutočnej pozitívnej reakcie (TPR) vs. mieru falošnej pozitivity (FPR) pri rôznych prahových hodnotách klasifikácie.
Oblasť pod krivkou Krivka (AUC):
AUC je skratka pre oblasť pod krivkou a krivka AUC predstavuje oblasť pod krivkou ROC. Meria celkovú výkonnosť modelu binárnej klasifikácie. Keďže TPR aj FPR sa pohybujú medzi 0 až 1, oblasť bude teda vždy ležať medzi 0 a 1 a vyššia hodnota AUC znamená lepší výkon modelu. Naším hlavným cieľom je maximalizovať túto oblasť, aby sme mali najvyššiu TPR a najnižšiu FPR na danej hranici. AUC meria pravdepodobnosť, že model priradí náhodne vybranému pozitívnemu prípadu vyššiu predpokladanú pravdepodobnosť v porovnaní s náhodne vybraným negatívnym prípadom.
Predstavuje pravdepodobnosť pomocou ktorých náš model dokáže rozlíšiť medzi dvoma triedami prítomnými v našom cieli.
Metrika hodnotenia klasifikácie ROC-AUC
Kľúčové pojmy používané v krivke AUC a ROC
1. TPR a FPR
Toto je najbežnejšia definícia, s ktorou by ste sa stretli pri vyhľadávaní AUC-ROC. Krivka ROC je v podstate graf, ktorý ukazuje výkonnosť klasifikačného modelu pri všetkých možných prahoch (prah je konkrétna hodnota, za ktorou hovoríte, že bod patrí do konkrétnej triedy). Krivka je vynesená medzi dvoma parametrami
- TPR – Skutočná pozitívna miera
- FPR – Falošne pozitívna miera
Predtým, ako pochopíme, TPR a FPR sa rýchlo pozrime na zmätená matica .
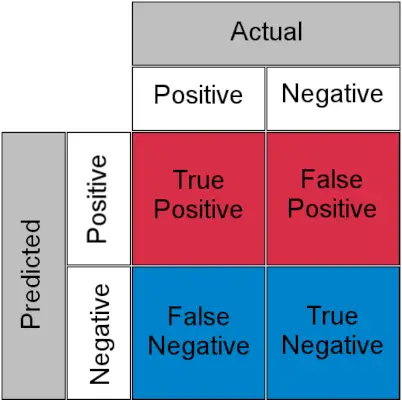
Matica zmätku pre klasifikačnú úlohu
- Skutočne pozitívne : Skutočné pozitívne a predpovedané ako pozitívne
- Skutočne negatívne : Skutočný negatívny a Predpovedaný ako negatívny
- Falošne pozitívne (chyba typu I) : Skutočný negatívny, ale predpokladaný ako pozitívny
- Falošný zápor (chyba typu II) : Skutočné pozitívne, ale predpovedané ako negatívne
Zjednodušene povedané, môžete nazvať falošne pozitívny a falošný poplach a falošne negatívne a chýbať . Teraz sa pozrime na to, čo sú TPR a FPR.
2. Citlivosť / True Positive Rate / Recall
TPR/Recall/Sensitivity je v podstate pomer pozitívnych príkladov, ktoré sú správne identifikované. Predstavuje schopnosť modelu správne identifikovať pozitívne prípady a vypočíta sa takto:

Sensitivity/Recall/TPR meria podiel skutočných pozitívnych prípadov, ktoré sú modelom správne identifikované ako pozitívne.
3. Falošne pozitívna miera
FPR je pomer negatívnych príkladov, ktoré sú nesprávne klasifikované.

čiastočná závislosť
4. Špecifickosť
Špecifickosť meria podiel skutočných negatívnych prípadov, ktoré model správne identifikuje ako negatívne. Predstavuje schopnosť modelu správne identifikovať negatívne prípady

A ako už bolo povedané, ROC nie je nič iné ako graf medzi TPR a FPR naprieč všetkými možnými prahmi a AUC je celá oblasť pod touto krivkou ROC.
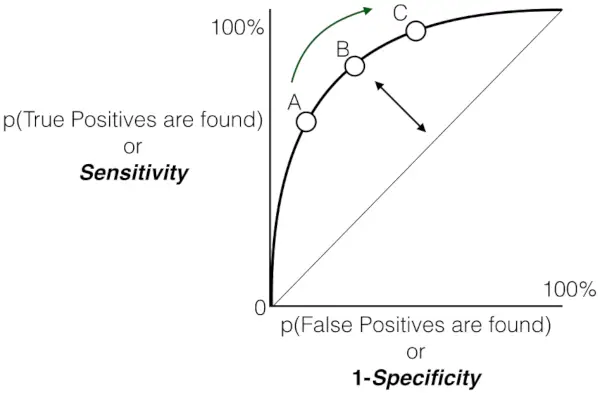
Graf citlivosti versus falošne pozitívna miera
Vzťah medzi citlivosťou, špecifickosťou, FPR a prahom .
Citlivosť a špecifickosť:
- Inverzný vzťah: citlivosť a špecifickosť majú inverzný vzťah. Keď sa jeden zvyšuje, druhý má tendenciu klesať. To odráža prirodzený kompromis medzi skutočnými pozitívnymi a skutočnými negatívnymi sadzbami.
- Ladenie pomocou prahu: Úpravou prahovej hodnoty môžeme kontrolovať rovnováhu medzi citlivosťou a špecifickosťou. Nižšie prahové hodnoty vedú k vyššej senzitivite (viac pravdivých pozitívnych výsledkov) na úkor špecifickosti (viac falošných pozitívnych výsledkov). Naopak, zvýšenie prahu zvyšuje špecifickosť (menej falošne pozitívnych výsledkov), ale obetuje citlivosť (viac falošných negatívnych výsledkov).
Prahová a falošne pozitívna miera (FPR):
- Pripojenie FPR a špecifickosti: Falošná pozitívna miera (FPR) je jednoducho doplnkom špecifickosti (FPR = 1 – špecifickosť). To znamená priamy vzťah medzi nimi: vyššia špecifickosť sa premieta do nižšej FPR a naopak.
- Zmeny FPR s TPR: Podobne, ako ste si všimli, True Positive Rate (TPR) a FPR sú tiež prepojené. Zvýšenie TPR (viac skutočných pozitívnych výsledkov) vo všeobecnosti vedie k zvýšeniu FPR (viac falošných pozitívnych výsledkov). Naopak, pokles TPR (menej skutočných pozitívnych výsledkov) má za následok pokles FPR (menej falošných pozitívnych výsledkov)
Ako funguje AUC-ROC?
Pozreli sme sa na geometrickú interpretáciu, ale myslím, že to stále nestačí na rozvíjanie intuície, čo v skutočnosti znamená 0,75 AUC, teraz sa pozrime na AUC-ROC z pravdepodobnostného hľadiska. Poďme sa najprv porozprávať o tom, čo robí AUC a neskôr na tom postavíme naše chápanie
AUC meria, ako dobre je model schopný rozlišovať medzi nimi triedy.
AUC 0,75 by v skutočnosti znamenalo, že povedzme, že vezmeme dva údajové body patriace do samostatných tried, potom existuje 75% šanca, že ich model bude schopný oddeliť alebo správne zoradiť, tj pozitívny bod má vyššiu pravdepodobnosť predpovede ako negatívny trieda. (za predpokladu vyššej pravdepodobnosti predikcie znamená, že bod by v ideálnom prípade patril do pozitívnej triedy). Tu je malý príklad, aby boli veci jasnejšie.
Index | Trieda | Pravdepodobnosť |
|---|---|---|
P1 | 1 | 0,95 |
P2 | 1 | 0,90 |
P3 | 0 | 0,85 |
P4 | 0 | 0,81 |
P5 | 1 | 0,78 |
P6 | 0 | 0,70 |
Tu máme 6 bodov, kde P1, P2 a P5 patria do triedy 1 a P3, P4 a P6 patria do triedy 0 a zodpovedajú nám predpovedané pravdepodobnosti v stĺpci Pravdepodobnosť, ako sme povedali, ak vezmeme dva body patriace do samostatného tried potom aká je pravdepodobnosť, že poradie modelu ich zoradí správne.
Zoberieme všetky možné dvojice tak, že jeden bod patrí do triedy 1 a druhý do triedy 0, budeme mať spolu 9 takýchto dvojíc nižšie je všetkých týchto 9 možných dvojíc.
Spárovať | je správne |
|---|---|
(P1,P3) | Áno |
(P1, P4) | Áno |
(P1, P6) | Áno |
(P2,P3) | Áno |
(P2, P4) | Áno |
(P2, P6) | Áno |
(P3, P5) | Nie |
(P4, P5) | Nie |
(P5,P6) | Áno |
Tu stĺpec Správne hovorí, či je uvedený pár správne zoradený na základe predpokladanej pravdepodobnosti, t.j. môžeme povedať, že existuje 77% šanca, že ak vyberiete pár bodov patriacich do samostatných tried, model ich dokáže správne rozlíšiť. Teraz si myslím, že za týmto číslom AUC môžete mať trochu intuície, len aby ste vyjasnili akékoľvek ďalšie pochybnosti, overme si to pomocou implementácie AUC-ROC programu Scikit learns.
Python3
import> numpy as np> from> sklearn .metrics>import> roc_auc_score> y_true>=> [>1>,>1>,>0>,>0>,>1>,>0>]> y_pred>=> [>0.95>,>0.90>,>0.85>,>0.81>,>0.78>,>0.70>]> auc>=> np.>round>(roc_auc_score(y_true, y_pred),>3>)> print>(>'Auc for our sample data is {}'>.>format>(auc))> |
>
>
Výkon:
AUC for our sample data is 0.778>
Kedy by sme mali použiť hodnotiacu metriku AUC-ROC?
V niektorých oblastiach nemusí byť použitie ROC-AUC ideálne. V prípadoch, keď je súbor údajov značne nevyvážený, krivka ROC môže poskytnúť príliš optimistické hodnotenie výkonu modelu . Toto skreslenie optimizmu vzniká, pretože miera falošných pozitív (FPR) krivky ROC môže byť veľmi malá, keď je počet skutočných negatívov veľký.
Pri pohľade na vzorec FPR,

pozorujeme ,
- Trieda negatívnych je vo väčšine, menovateľom FPR dominujú True Negatives, kvôli ktorým sa FPR stáva menej citlivou na zmeny v predpovediach týkajúcich sa menšinovej triedy (pozitívna trieda).
- Krivky ROC môžu byť vhodné, keď sú náklady na falošné pozitíva a falošné negatíva vyvážené a súbor údajov nie je výrazne nevyvážený.
V takom prípade Precision-Recall Curves môžu byť použité, ktoré poskytujú alternatívnu hodnotiacu metriku, ktorá je vhodnejšia pre nevyvážené súbory údajov, so zameraním na výkonnosť klasifikátora vzhľadom na pozitívnu (menšinovú) triedu.
Špekuluje sa o výkone modelu
- Vysoká AUC (blízka 1) indikuje vynikajúcu rozlišovaciu schopnosť. To znamená, že model je účinný pri rozlišovaní medzi týmito dvoma triedami a jeho predpovede sú spoľahlivé.
- Nízka AUC (blízka 0) naznačuje slabý výkon. V tomto prípade má model problém odlíšiť pozitívne a negatívne triedy a jeho predpovede nemusia byť dôveryhodné.
- AUC okolo 0,5 znamená, že model v podstate robí náhodné odhady. Neukazuje žiadnu schopnosť oddeliť triedy, čo naznačuje, že model sa neučí žiadne zmysluplné vzorce z údajov.
Pochopenie krivky AUC-ROC
V ROC krivke os x zvyčajne predstavuje falošnú pozitívnu mieru (FPR) a os y predstavuje skutočnú pozitívnu mieru (TPR), tiež známu ako citlivosť alebo spätné vyvolanie. Vyššia hodnota osi x (smerom doprava) na krivke ROC teda znamená vyššiu mieru falošne pozitívnych výsledkov a vyššia hodnota osi y (smerom hore) znamená vyššiu mieru skutočne pozitívnych výsledkov. Krivka ROC je grafická znázornenie kompromisu medzi mierou skutočne pozitívnych a falošne pozitívnych výsledkov pri rôznych prahoch. Ukazuje výkonnosť klasifikačného modelu pri rôznych klasifikačných prahoch. AUC (plocha pod krivkou) je súhrnným meradlom výkonnosti krivky ROC. Výber prahu závisí od špecifických požiadaviek problému, ktorý sa pokúšate vyriešiť, a od kompromisu medzi falošne pozitívnymi a falošne negatívnymi výsledkami, ktorý je prijateľné vo vašom kontexte.
- Ak chcete uprednostniť zníženie falošne pozitívnych výsledkov (minimalizáciu šancí označiť niečo ako pozitívne, keď to tak nie je), môžete si vybrať hranicu, ktorá vedie k nižšej miere falošných pozitívnych výsledkov.
- Ak chcete uprednostniť zvyšovanie skutočných pozitívnych výsledkov (zachytenie čo najväčšieho počtu skutočných pozitívnych výsledkov), môžete si vybrať hranicu, ktorá vedie k vyššej skutočnej pozitívnej miere.
Pozrime sa na príklad na ilustráciu toho, ako sa ROC krivky generujú pre rôzne prahové hodnoty a ako konkrétny prah zodpovedá matici zmätku. Predpokladajme, že máme a problém binárnej klasifikácie s modelom predpovedajúcim, či je e-mail spam (pozitívny) alebo nie je spam (negatívny).
Zoberme si hypotetické údaje,
Skutočné označenia: [1, 0, 1, 0, 1, 1, 0, 0, 1, 0]
Predpokladané pravdepodobnosti: [0,8, 0,3, 0,6, 0,2, 0,7, 0,9, 0,4, 0,1, 0,75, 0,55]
Prípad 1: Prah = 0,5
Skutočné štítky | Predpovedané pravdepodobnosti | Predpokladané štítky |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Matica zmätku založená na vyššie uvedených predpovediach
| Predpoveď = 0 | Predpoveď = 1 |
|---|---|---|
Skutočné = 0 | TP = 4 | FN=1 |
Skutočné = 1 | FP = 0 | TN = 5 |
v súlade s tým
- Skutočná pozitívna miera (TPR) :
Podiel skutočných pozitív správne identifikovaných klasifikátorom je

- Falošná pozitívna miera (FPR) :
Podiel skutočných negatív nesprávne klasifikovaných ako pozitíva



Takže na hranici 0,5:
- Skutočná pozitívna miera (citlivosť): 0,8
- Miera falošne pozitívnych výsledkov: 0
Interpretácia je taká, že model pri tejto prahovej hodnote správne identifikuje 80 % skutočných pozitívnych výsledkov (TPR), ale nesprávne klasifikuje 0 % skutočných negatív ako pozitíva (FPR).
Podľa toho pre rôzne prahové hodnoty dostaneme,
Prípad 2: Prah = 0,7
Skutočné štítky | Predpovedané pravdepodobnosti | Predpokladané štítky |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 0 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 0 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 0 |
Matica zmätku založená na vyššie uvedených predpovediach
| Predpoveď = 0 | Predpoveď = 1 |
|---|---|---|
Skutočné = 0 | TP = 5 | FN=0 |
Skutočné = 1 | FP = 2 | TN = 3 |
v súlade s tým
- Skutočná pozitívna miera (TPR) :
Podiel skutočných pozitív správne identifikovaných klasifikátorom je

- Falošná pozitívna miera (FPR) :
Podiel skutočných negatív nesprávne klasifikovaných ako pozitíva



Prípad 3: Prah = 0,4
Skutočné štítky | Predpovedané pravdepodobnosti | Predpokladané štítky |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Matica zmätku založená na vyššie uvedených predpovediach
| Predpoveď = 0 | Predpoveď = 1 |
|---|---|---|
Skutočné = 0 | TP = 4 | FN=1 |
Skutočné = 1 | FP = 0 | TN = 5 |
v súlade s tým
- Skutočná pozitívna miera (TPR) :
Podiel skutočných pozitív správne identifikovaných klasifikátorom je
- Falošná pozitívna miera (FPR) :
Podiel skutočných negatív nesprávne klasifikovaných ako pozitíva
Prípad 4: Prah = 0,2
Skutočné štítky | Predpovedané pravdepodobnosti | Predpokladané štítky |
|---|---|---|
| 1 | 0,8 | 1 linuxový príkaz make |
| 0 | 0,3 | 1 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 1 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Matica zmätku založená na vyššie uvedených predpovediach
| Predpoveď = 0 | Predpoveď = 1 |
|---|---|---|
Skutočné = 0 | TP = 2 | FN=3 |
Skutočné = 1 | FP = 0 | TN = 5 |
v súlade s tým
- Skutočná pozitívna miera (TPR) :
Podiel skutočných pozitív správne identifikovaných klasifikátorom je

- Falošná pozitívna miera (FPR) :
Podiel skutočných negatív nesprávne klasifikovaných ako pozitíva

Prípad 5: Prah = 0,85
Skutočné štítky | Predpovedané pravdepodobnosti | Predpokladané štítky |
|---|---|---|
| 1 | 0,8 | 0 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 0 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 0 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 0 |
| 0 | 0,55 ako previesť reťazec na celé číslo v jave | 0 |
Matica zmätku založená na vyššie uvedených predpovediach
| Predpoveď = 0 | Predpoveď = 1 |
|---|---|---|
Skutočné = 0 | TP = 5 | FN=0 |
Skutočné = 1 | FP = 4 | TN = 1 |
v súlade s tým
- Skutočná pozitívna miera (TPR) :
Podiel skutočných pozitív správne identifikovaných klasifikátorom je
- Falošná pozitívna miera (FPR) :
Podiel skutočných negatív nesprávne klasifikovaných ako pozitíva


Na základe vyššie uvedeného výsledku vynesieme ROC krivku
Python3
true_positive_rate>=> [>0.4>,>0.8>,>0.8>,>1.0>,>1>]> false_positive_rate>=> [>0>,>0>,>0>,>0.2>,>0.8>]> plt.plot(false_positive_rate, true_positive_rate,>'o-'>, label>=>'ROC'>)> plt.plot([>0>,>1>], [>0>,>1>],>'--'>, color>=>'grey'>, label>=>'Worst case'>)> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curve'>)> plt.legend()> plt.show()> |
>
>
Výkon:
Z grafu vyplýva, že:
- Sivá prerušovaná čiara predstavuje scenár najhoršieho prípadu, kde sú predpovede modelu, tj TPR sú FPR, rovnaké. Táto diagonálna čiara sa považuje za najhorší scenár, čo naznačuje rovnakú pravdepodobnosť falošne pozitívnych a falošných negatívnych výsledkov.
- Keď sa body odchyľujú od čiary náhodného odhadu smerom k ľavému hornému rohu, výkon modelu sa zlepšuje.
- Oblasť pod krivkou (AUC) je kvantitatívna miera rozlišovacej schopnosti modelu. Vyššia hodnota AUC, bližšia k 1,0, naznačuje vynikajúci výkon. Najlepšia možná hodnota AUC je 1,0, čo zodpovedá modelu, ktorý dosahuje 100 % senzitivitu a 100 % špecifickosť.
Celkovo krivka prevádzkovej charakteristiky prijímača (ROC) slúži ako grafické znázornenie kompromisu medzi skutočnou pozitívnou mierou (citlivosťou) a falošne pozitívnou mierou binárneho klasifikačného modelu pri rôznych rozhodovacích prahoch. Keď krivka elegantne stúpa smerom k ľavému hornému rohu, znamená to chvályhodnú schopnosť modelu rozlišovať medzi pozitívnymi a negatívnymi prípadmi naprieč celým radom prahov spoľahlivosti. Táto dráha smerom nahor naznačuje zlepšený výkon, pričom sa dosiahla vyššia citlivosť pri minimalizácii falošných poplachov. Anotované prahové hodnoty, označené ako A, B, C, D a E, ponúkajú cenné informácie o dynamickom správaní modelu na rôznych úrovniach spoľahlivosti.
Implementácia pomocou dvoch rôznych modelov
Inštalácia knižníc
Python3
import> numpy as np> import> pandas as pd> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> |
>
>
S cieľom trénovať Náhodný les a Logistická regresia Algoritmus vytvára umelé binárne klasifikačné údaje na prezentáciu ich ROC kriviek so skóre AUC.
Generovanie údajov a rozdelenie údajov
Python3
# Generate synthetic data for demonstration> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>2>, random_state>=>42>)> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y, test_size>=>0.2>, random_state>=>42>)> |
>
>
Pomocou deliaceho pomeru 80-20 algoritmus vytvára umelé binárne klasifikačné údaje s 20 funkciami, rozdeľuje ich do tréningových a testovacích sád a priraďuje náhodné semeno na zabezpečenie reprodukovateľnosti.
Školenie rôznych modelov
Python3
# Train two different models> logistic_model>=> LogisticRegression(random_state>=>42>)> logistic_model.fit(X_train, y_train)> random_forest_model>=> RandomForestClassifier(n_estimators>=>100>, random_state>=>42>)> random_forest_model.fit(X_train, y_train)> |
>
>
Pomocou pevného náhodného zdroja na zabezpečenie opakovateľnosti metóda inicializuje a trénuje model logistickej regresie na trénovacej množine. Podobným spôsobom používa trénovacie údaje a rovnaký náhodný zdroj na inicializáciu a trénovanie modelu Random Forest so 100 stromami.
Predpovede
Python3
# Generate predictions> y_pred_logistic>=> logistic_model.predict_proba(X_test)[:,>1>]> y_pred_rf>=> random_forest_model.predict_proba(X_test)[:,>1>]> |
>
>
Pomocou testovacích údajov a vyškolených Logistická regresia kód predpovedá pravdepodobnosť pozitívnej triedy. Podobným spôsobom, s použitím testovacích údajov, používa trénovaný model Random Forest na vytvorenie projektovaných pravdepodobností pre pozitívnu triedu.
Vytvorenie dátového rámca
Python3
# Create a DataFrame> test_df>=> pd.DataFrame(> >{>'True'>: y_test,>'Logistic'>: y_pred_logistic,>'RandomForest'>: y_pred_rf})> |
>
>
Pomocou testovacích údajov kód vytvorí DataFrame s názvom test_df so stĺpcami označenými True, Logistic a RandomForest, pričom pridá pravdivé označenia a predpovedané pravdepodobnosti z modelov Random Forest a Logistic Regression.
Nakreslite krivku ROC pre modely
Python3
# Plot ROC curve for each model> plt.figure(figsize>=>(>7>,>5>))> for> model>in> [>'Logistic'>,>'RandomForest'>]:> >fpr, tpr, _>=> roc_curve(test_df[>'True'>], test_df[model])> >roc_auc>=> auc(fpr, tpr)> >plt.plot(fpr, tpr, label>=>f>'{model} (AUC = {roc_auc:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'r--'>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curves for Two Models'>)> plt.legend()> plt.show()> |
>
>
Výkon:

Kód generuje graf s číslami 8 x 6 palcov. Vypočítava krivku AUC a ROC pre každý model (náhodná lesná a logistická regresia), potom vykreslí krivku ROC. The ROC krivka pre náhodné hádanie je znázornená aj červená prerušovaná čiara a na vizualizáciu sú nastavené štítky, nadpis a legenda.
Ako použiť ROC-AUC pre viactriedny model?
Pre nastavenie viacerých tried môžeme jednoducho použiť metodológiu jedna vs všetky a pre každú triedu budete mať jednu ROC krivku. Povedzme, že máte štyri triedy A, B, C a D, potom by existovali krivky ROC a zodpovedajúce hodnoty AUC pre všetky štyri triedy, t. j. raz by A bola jedna trieda a kombinácia B, C a D by boli ostatné triedy. , podobne B je jedna trieda a A, C a D kombinované ako ostatné triedy atď.
Všeobecné kroky na používanie AUC-ROC v kontexte modelu klasifikácie viacerých tried sú:
Metodika jedna proti všetkým:
- Pre každú triedu vo vašom probléme s viacerými triedami s ňou zaobchádzajte ako s pozitívnou triedou, zatiaľ čo všetky ostatné triedy skombinujte do negatívnej triedy.
- Trénujte binárny klasifikátor pre každú triedu oproti ostatným triedam.
Vypočítajte AUC-ROC pre každú triedu:
- Tu vykreslíme ROC krivku pre danú triedu oproti zvyšku.
- Vyneste ROC krivky pre každú triedu do rovnakého grafu. Každá krivka predstavuje diskriminačný výkon modelu pre konkrétnu triedu.
- Preskúmajte skóre AUC pre každú triedu. Vyššie skóre AUC naznačuje lepšiu diskrimináciu pre túto konkrétnu triedu.
Implementácia AUC-ROC vo viactriednej klasifikácii
Importovanie knižníc
Python3
import> numpy as np> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.preprocessing>import> label_binarize> from> sklearn.multiclass>import> OneVsRestClassifier> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> from> itertools>import> cycle> |
>
>
Program vytvorí umelé viactriedne dáta, rozdelí ich do trénovacích a testovacích sád a následne použije One-vs-Restclassifier technika na trénovanie klasifikátorov pre náhodný les a logistickú regresiu. Nakoniec vykresľuje viactriedne ROC krivky dvoch modelov, aby preukázal, ako dobre rozlišujú medzi rôznymi triedami.
Generovanie dát a rozdelenie
Python3
# Generate synthetic multiclass data> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>3>, n_informative>=>10>, random_state>=>42>)> # Binarize the labels> y_bin>=> label_binarize(y, classes>=>np.unique(y))> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y_bin, test_size>=>0.2>, random_state>=>42>)> |
>
>
Tri triedy a dvadsať funkcií tvoria syntetické viactriedne údaje produkované kódom. Po binarizácii štítkov sa údaje rozdelia do tréningových a testovacích sád v pomere 80-20.
Tréningové modely
Python3
# Train two different multiclass models> logistic_model>=> OneVsRestClassifier(LogisticRegression(random_state>=>42>))> logistic_model.fit(X_train, y_train)> rf_model>=> OneVsRestClassifier(> >RandomForestClassifier(n_estimators>=>100>, random_state>=>42>))> rf_model.fit(X_train, y_train)> |
>
>
Program trénuje dva modely viacerých tried: model Random Forest so 100 odhadmi a model logistickej regresie s Prístup jeden vs . S trénovacím súborom údajov sú vybavené oba modely.
Vykreslenie krivky AUC-ROC
Python3
# Compute ROC curve and ROC area for each class> fpr>=> dict>()> tpr>=> dict>()> roc_auc>=> dict>()> models>=> [logistic_model, rf_model]> plt.figure(figsize>=>(>6>,>5>))> colors>=> cycle([>'aqua'>,>'darkorange'>])> for> model, color>in> zip>(models, colors):> >for> i>in> range>(model.classes_.shape[>0>]):> >fpr[i], tpr[i], _>=> roc_curve(> >y_test[:, i], model.predict_proba(X_test)[:, i])> >roc_auc[i]>=> auc(fpr[i], tpr[i])> >plt.plot(fpr[i], tpr[i], color>=>color, lw>=>2>,> >label>=>f>'{model.__class__.__name__} - Class {i} (AUC = {roc_auc[i]:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'k--'>, lw>=>2>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'Multiclass ROC Curve with Logistic Regression and Random Forest'>)> plt.legend(loc>=>'lower right'>)> plt.show()> |
>
>
Výkon:

Krivky ROC a skóre AUC modelov náhodného lesa a logistickej regresie sú vypočítané kódom pre každú triedu. Krivky ROC s viacerými triedami sa potom vynesú do grafu, pričom znázornia diskriminačný výkon každej triedy a obsahujú čiaru, ktorá predstavuje náhodné hádanie. Výsledný graf ponúka grafické vyhodnotenie klasifikácie modelov.
Záver
V rámci strojového učenia sa výkonnosť modelov binárnej klasifikácie hodnotí pomocou kľúčovej metriky nazývanej prevádzková charakteristika oblasti pod prijímačom (AUC-ROC). Naprieč rôznymi rozhodovacími prahmi ukazuje, ako sa vymieňa citlivosť a špecifickosť. Väčšiu diskrimináciu medzi pozitívnymi a negatívnymi prípadmi zvyčajne vykazuje model s vyšším skóre AUC. Zatiaľ čo 0,5 znamená šancu, 1 predstavuje bezchybný výkon. Optimalizácia a výber modelu sú podporované užitočnými informáciami, ktoré krivka AUC-ROC ponúka o schopnosti modelu rozlišovať medzi triedami. Pri práci s nevyváženými súbormi údajov alebo aplikáciami, kde falošne pozitívne a falošne negatívne výsledky majú rôzne náklady, je to obzvlášť užitočné ako komplexné opatrenie.
Časté otázky pre krivku AUC ROC v strojovom učení
1. Čo je krivka AUC-ROC?
Pre rôzne prahové hodnoty klasifikácie je kompromis medzi mierou skutočnej pozitívnej reakcie (citlivosťou) a mierou falošnej pozitivity (špecifickosť) graficky znázornený krivkou AUC-ROC.
2. Ako vyzerá dokonalá krivka AUC-ROC?
Oblasť 1 na ideálnej krivke AUC-ROC by znamenala, že model dosahuje optimálnu citlivosť a špecifickosť pri všetkých prahoch.
3. Čo znamená hodnota AUC 0,5?
AUC 0,5 znamená, že výkon modelu je porovnateľný s výkonom náhodnej náhody. To naznačuje nedostatok rozlišovacej schopnosti.
4. Môže sa AUC-ROC použiť na klasifikáciu viacerých tried?
AUC-ROC sa často používa na otázky týkajúce sa binárnej klasifikácie. Variácie, ako je makropriemer alebo mikropriemer AUC, sa môžu brať do úvahy pri klasifikácii viacerých tried.
5. Ako je krivka AUC-ROC užitočná pri hodnotení modelu?
Schopnosť modelu rozlišovať medzi triedami je komplexne zhrnutá krivkou AUC-ROC. Pri práci s nevyváženými množinami údajov je to obzvlášť užitočné.