Neinformované vyhľadávanie je trieda všeobecných vyhľadávacích algoritmov, ktoré fungujú hrubou silou. Neinformované vyhľadávacie algoritmy nemajú ďalšie informácie o stave alebo vyhľadávacom priestore okrem toho, ako prejsť stromom, takže sa nazýva aj slepé vyhľadávanie.
Nasledujú rôzne typy neinformovaných vyhľadávacích algoritmov:
1. Hľadanie do šírky:
- Vyhľadávanie do šírky je najbežnejšou stratégiou vyhľadávania na prechádzanie stromom alebo grafom. Tento algoritmus vyhľadáva po šírke v strome alebo grafe, preto sa nazýva vyhľadávanie na šírku.
- Algoritmus BFS začne hľadať od koreňového uzla stromu a rozšíri všetky nástupnícke uzly na aktuálnej úrovni pred prechodom na uzly ďalšej úrovne.
- Algoritmus vyhľadávania do šírky je príkladom algoritmu vyhľadávania všeobecného grafu.
- Široké vyhľadávanie implementované pomocou dátovej štruktúry frontu FIFO.
Výhody:
- BFS poskytne riešenie, ak nejaké riešenie existuje.
- Ak existuje viac ako jedno riešenie pre daný problém, potom BFS poskytne minimálne riešenie, ktoré vyžaduje najmenší počet krokov.
Nevýhody:
- Vyžaduje si to veľa pamäte, pretože každá úroveň stromu musí byť uložená do pamäte, aby sa rozšírila ďalšia úroveň.
- BFS potrebuje veľa času, ak je riešenie ďaleko od koreňového uzla.
Príklad:
V nižšie uvedenej stromovej štruktúre sme ukázali prechádzanie stromu pomocou algoritmu BFS z koreňového uzla S do cieľového uzla K. Algoritmus vyhľadávania BFS prechádza vo vrstvách, takže bude sledovať cestu, ktorá je znázornená bodkovanou šípkou a prejdená cesta bude:
S---> A--->B---->C--->D---->G--->H--->E---->F---->I---->K
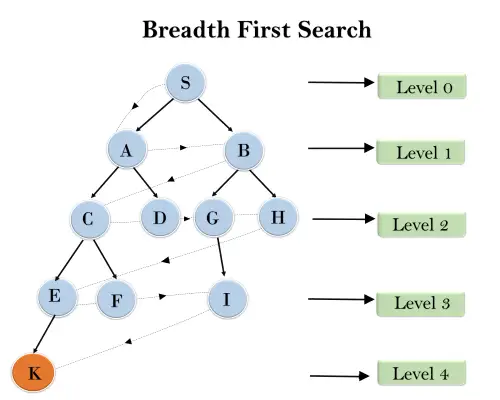
Časová zložitosť: Časová zložitosť algoritmu BFS môže byť získaná počtom uzlov prejdených v BFS až po najplytší uzol. Kde d = hĺbka najplytšieho riešenia a b je uzol v každom stave.
T(b) = 1+b2+b3+.......+ bd= O (bd)
Priestorová zložitosť: Priestorová zložitosť algoritmu BFS je daná veľkosťou pamäte hranice, ktorá je O(bd).
Úplnosť: BFS je dokončené, čo znamená, že ak je najplytší cieľový uzol v určitej konečnej hĺbke, potom BFS nájde riešenie.
Optimalita: BFS je optimálny, ak náklady na cestu sú neklesajúcou funkciou hĺbky uzla.
2. Hĺbkové vyhľadávanie
- Hĺbkové vyhľadávanie je rekurzívny algoritmus na prechádzanie stromovou alebo grafovou dátovou štruktúrou.
- Nazýva sa to vyhľadávanie v prvej hĺbke, pretože začína od koreňového uzla a sleduje každú cestu k uzlu s najväčšou hĺbkou pred prechodom na ďalšiu cestu.
- DFS používa na svoju implementáciu zásobníkovú dátovú štruktúru.
- Proces algoritmu DFS je podobný algoritmu BFS.
Poznámka: Backtracking je technika algoritmu na nájdenie všetkých možných riešení pomocou rekurzie.
Výhoda:
- DFS vyžaduje veľmi menej pamäte, pretože potrebuje iba uložiť zásobník uzlov na ceste od koreňového uzla k aktuálnemu uzlu.
- Dosiahnutie cieľového uzla trvá menej času ako algoritmu BFS (ak prechádza správnou cestou).
Nevýhoda:
- Existuje možnosť, že mnohé štáty sa budú opakovať a neexistuje žiadna záruka nájdenia riešenia.
- Algoritmus DFS sa zameriava na hlboké vyhľadávanie a niekedy môže prejsť do nekonečnej slučky.
Príklad:
V nižšie uvedenom strome vyhľadávania sme ukázali tok hĺbkového vyhľadávania, ktorý bude nasledovať v tomto poradí:
najkrajší úsmev
Koreňový uzol ---> Ľavý uzol ----> pravý uzol.
Začne hľadať od koreňového uzla S a prejde A, potom B, potom D a E, po prejdení E sa vráti späť do stromu, pretože E nemá žiadneho ďalšieho nástupcu a cieľový uzol sa stále nenájde. Po návrate prejde uzlom C a potom G a tu skončí, keď našiel cieľový uzol.

Úplnosť: Algoritmus vyhľadávania DFS je dokončený v konečnom stavovom priestore, pretože rozšíri každý uzol v rámci obmedzeného vyhľadávacieho stromu.
Časová zložitosť: Časová zložitosť DFS bude ekvivalentná uzlu, ktorým algoritmus prechádza. Je to dané:
T(n)= 1+ n2+ n3.........+ nm=O(nm)
Kde, m = maximálna hĺbka akéhokoľvek uzla a môže byť oveľa väčšia ako d (najmenší hĺbka riešenia)
Priestorová zložitosť: Algoritmus DFS potrebuje ukladať iba jednu cestu z koreňového uzla, takže priestorová zložitosť DFS je ekvivalentná veľkosti množiny okrajov, čo je O .
Optimálne: Algoritmus vyhľadávania DFS nie je optimálny, pretože môže generovať veľký počet krokov alebo vysoké náklady na dosiahnutie cieľového uzla.
3. Algoritmus vyhľadávania s obmedzenou hĺbkou:
Algoritmus hľadania s obmedzenou hĺbkou je podobný hľadaniu do hĺbky s vopred stanoveným limitom. Hĺbkovo obmedzené vyhľadávanie môže vyriešiť nevýhodu nekonečnej cesty pri vyhľadávaní do hĺbky. V tomto algoritme bude uzol na hĺbkovom limite zaobchádzať tak, že nemá žiadne ďalšie uzly.
Hĺbkovo obmedzené vyhľadávanie možno ukončiť dvoma podmienkami zlyhania:
- Štandardná hodnota zlyhania: Znamená, že problém nemá žiadne riešenie.
- Hodnota medzného zlyhania: Nedefinuje žiadne riešenie problému v rámci daného limitu hĺbky.
Výhody:
Hĺbkovo obmedzené vyhľadávanie je efektívne z hľadiska pamäte.
Nevýhody:
- Hĺbkovo obmedzené vyhľadávanie má aj nevýhodu v neúplnosti.
- Nemusí byť optimálne, ak má problém viac ako jedno riešenie.
Príklad:

Úplnosť: Algoritmus vyhľadávania DLS je dokončený, ak je riešenie nad hĺbkovým limitom.
Časová zložitosť: Časová zložitosť algoritmu DLS je O(bℓ) .
Priestorová zložitosť: Priestorová zložitosť algoritmu DLS je O (b�ℓ) .
Optimálne: Hĺbkovo obmedzené vyhľadávanie možno považovať za špeciálny prípad DFS a tiež nie je optimálne, aj keď ℓ>d.
4. Algoritmus vyhľadávania s jednotnou cenou:
Vyhľadávanie jednotných nákladov je vyhľadávací algoritmus používaný na prechádzanie váženým stromom alebo grafom. Tento algoritmus vstupuje do hry, keď je pre každú hranu k dispozícii iná cena. Primárnym cieľom vyhľadávania jednotných nákladov je nájsť cestu k cieľovému uzlu, ktorý má najnižšie kumulatívne náklady. Vyhľadávanie jednotných nákladov rozširuje uzly podľa ich nákladov na cestu z koreňového uzla. Dá sa použiť na riešenie akéhokoľvek grafu/stromu, kde sú požadované optimálne náklady. Algoritmus vyhľadávania s jednotnou cenou je implementovaný prioritným frontom. Maximálnu prioritu dáva najnižším kumulovaným nákladom. Jednotné vyhľadávanie nákladov je ekvivalentné algoritmu BFS, ak sú náklady na cestu všetkých hrán rovnaké.
Výhody:
- Jednotné vyhľadávanie nákladov je optimálne, pretože v každom štáte sa vyberie cesta s najnižšími nákladmi.
Nevýhody:
- Nezáleží na počte krokov potrebných pri hľadaní a zaujíma sa len o náklady na cestu. Vďaka tomu sa tento algoritmus môže zaseknúť v nekonečnej slučke.
Príklad:

Úplnosť:
Jednotné vyhľadávanie nákladov je dokončené, napríklad ak existuje riešenie, UCS ho nájde.
Časová zložitosť:
Nech C* sú náklady na optimálne riešenie a e je každý krok k priblíženiu sa k cieľovému uzlu. Potom je počet krokov = C*/ε+1. Tu sme vzali +1, pretože začíname od stavu 0 a končíme na C*/ε.
Najhorším prípadom je časová zložitosť vyhľadávania jednotných nákladov O(b1 + [C*/e])/ .
Priestorová zložitosť:
int parseint
Rovnaká logika platí pre priestorovú zložitosť, takže najhorší prípad priestorovej zložitosti pri hľadaní jednotných nákladov je O(b1 + [C*/e]) .
Optimálne:
Vyhľadávanie jednotných nákladov je vždy optimálne, pretože vyberá iba cestu s najnižšou cenou.
5. Iteratívne prehlbovanie hĺbka-prvé vyhľadávanie:
Algoritmus iteratívneho prehĺbenia je kombináciou algoritmov DFS a BFS. Tento vyhľadávací algoritmus zistí najlepší hĺbkový limit a robí to postupným zvyšovaním limitu, kým sa nenájde cieľ.
Tento algoritmus vykonáva hĺbkové vyhľadávanie až do určitého „hĺbkového limitu“ a po každej iterácii neustále zvyšuje hĺbkový limit, kým sa nenájde cieľový uzol.
Tento vyhľadávací algoritmus kombinuje výhody rýchleho vyhľadávania do šírky a pamäťovej efektivity vyhľadávania na prvom mieste.
Iteračný vyhľadávací algoritmus je užitočné neinformované vyhľadávanie, keď je vyhľadávací priestor veľký a hĺbka cieľového uzla nie je známa.
Výhody:
- Kombinuje výhody vyhľadávacieho algoritmu BFS a DFS, pokiaľ ide o rýchle vyhľadávanie a efektivitu pamäte.
Nevýhody:
- Hlavnou nevýhodou IDDFS je, že opakuje všetku prácu predchádzajúcej fázy.
Príklad:
Nasledujúca stromová štruktúra ukazuje iteratívne prehĺbenie hĺbkového vyhľadávania. Algoritmus IDDFS vykonáva rôzne iterácie, kým nenájde cieľový uzol. Iterácia vykonaná algoritmom je daná ako:

1. iterácia -----> A
2. iterácia ----> A, B, C
3. iterácia ------> A, B, D, E, C, F, G
4. iterácia------>A, B, D, H, I, E, C, F, K, G
V štvrtej iterácii algoritmus nájde cieľový uzol.
Úplnosť:
Tento algoritmus je úplný, ak je faktor vetvenia konečný.
Časová zložitosť:
Predpokladajme, že b je faktor vetvenia a hĺbka je d, potom je časová zložitosť v najhoršom prípade O(bd) .
Priestorová zložitosť:
Priestorová zložitosť IDDFS bude O(bd) .
Optimálne:
Algoritmus IDDFS je optimálny, ak cena cesty je neklesajúcou funkciou hĺbky uzla.
6. Obojsmerný vyhľadávací algoritmus:
Algoritmus obojsmerného vyhľadávania spúšťa dve súčasné vyhľadávania, jedno z počiatočného stavu nazývaného ako dopredné vyhľadávanie a druhé z cieľového uzla nazývané ako spätné vyhľadávanie, aby sa našiel cieľový uzol. Obojsmerné vyhľadávanie nahrádza jeden jediný vyhľadávací graf dvoma malými podgrafmi, v ktorých jeden začína vyhľadávanie od počiatočného vrcholu a druhý začína od cieľového vrcholu. Vyhľadávanie sa zastaví, keď sa tieto dva grafy pretnú.
Obojsmerné vyhľadávanie môže využívať vyhľadávacie techniky ako BFS, DFS, DLS atď.
Výhody:
virtuálna pamäť
- Obojsmerné vyhľadávanie je rýchle.
- Obojsmerné vyhľadávanie vyžaduje menej pamäte
Nevýhody:
- Implementácia obojsmerného vyhľadávacieho stromu je náročná.
Príklad:
V nižšie uvedenom strome vyhľadávania je použitý obojsmerný vyhľadávací algoritmus. Tento algoritmus rozdeľuje jeden graf/strom na dva podgrafy. Začína prechádzať z uzla 1 smerom dopredu a začína z cieľového uzla 16 smerom dozadu.
Algoritmus končí v uzle 9, kde sa stretávajú dve vyhľadávania.

Úplnosť: Obojsmerné vyhľadávanie je dokončené, ak použijeme BFS v oboch vyhľadávaniach.
Časová zložitosť: Časová náročnosť obojsmerného vyhľadávania pomocou BFS je O(bd) .
Priestorová zložitosť: Priestorová zložitosť obojsmerného vyhľadávania je O(bd) .
Optimálne: Obojsmerné vyhľadávanie je optimálne.