Nasledujúca architektúra vysvetľuje tok odoslania dotazu do Hive.
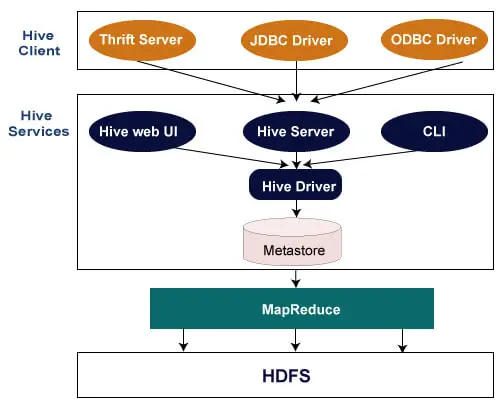
Klient Hive
Hive umožňuje písanie aplikácií v rôznych jazykoch vrátane Java, Python a C++. Podporuje rôzne typy klientov, ako napríklad: -
- Thrift Server – Ide o platformu poskytovateľa služieb pre viacero jazykov, ktorá slúži na požiadavky všetkých programovacích jazykov, ktoré podporujú Thrift.
- JDBC Driver – Používa sa na vytvorenie spojenia medzi úľom a Java aplikáciami. Ovládač JDBC je prítomný v triede org.apache.hadoop.hive.jdbc.HiveDriver.
- ODBC Driver – Umožňuje aplikáciám, ktoré podporujú protokol ODBC, pripojiť sa k Hive.
Úľové služby
Nasledujúce služby poskytuje Hive: -
- Hive CLI – Hive CLI (Command Line Interface) je shell, v ktorom môžeme vykonávať Hive dotazy a príkazy.
- Webové používateľské rozhranie Hive – Webové používateľské rozhranie Hive je len alternatívou Hive CLI. Poskytuje webové GUI na vykonávanie dotazov a príkazov Hive.
- Hive MetaStore - Je to centrálne úložisko, ktoré ukladá všetky informácie o štruktúre rôznych tabuliek a oddielov v sklade. Zahŕňa tiež metadáta stĺpca a informácie o jeho type, serializátory a deserializátory, ktoré sa používajú na čítanie a zapisovanie údajov, a príslušné súbory HDFS, v ktorých sú údaje uložené.
- Hive Server – Označuje sa ako Apache Thrift Server. Prijíma požiadavku od rôznych klientov a poskytuje ju Hive Driver.
- Hive Driver – Prijíma dotazy z rôznych zdrojov, ako je webové používateľské rozhranie, CLI, Thrift a ovládač JDBC/ODBC. Prenesie dotazy do kompilátora.
- Hive Compiler – Účelom kompilátora je analyzovať dotaz a vykonávať sémantickú analýzu rôznych blokov dotazov a výrazov. Konvertuje príkazy HiveQL na úlohy MapReduce.
- Hive Execution Engine - Optimizer generuje logický plán vo forme DAG úloh na redukciu mapy a úloh HDFS. Nakoniec vykonávací mechanizmus vykoná prichádzajúce úlohy v poradí ich závislostí.