Čo je vyrovnávacia pamäť LRU?
Algoritmy na nahradenie vyrovnávacej pamäte sú efektívne navrhnuté tak, aby nahradili vyrovnávaciu pamäť, keď je miesto plné. The Najmenej nedávno použité (LRU) je jedným z týchto algoritmov. Ako už názov napovedá, keď je vyrovnávacia pamäť plná, LRU vyberie údaje, ktoré boli naposledy použité, a odstráni ich, aby sa vytvoril priestor pre nové údaje. Priorita údajov vo vyrovnávacej pamäti sa mení podľa potreby týchto údajov, t. j. ak sa niektoré údaje načítajú alebo aktualizujú nedávno, priorita týchto údajov by sa zmenila a priradila by sa najvyššej priorite a priorita údajov sa zníži, ak zostáva nevyužité operácie po operáciách.
Obsah
- Čo je vyrovnávacia pamäť LRU?
- Operácie na vyrovnávacej pamäti LRU:
- Fungovanie vyrovnávacej pamäte LRU:
- Spôsoby implementácie vyrovnávacej pamäte LRU:
- Implementácia vyrovnávacej pamäte LRU pomocou frontu a hashovania:
- Implementácia vyrovnávacej pamäte LRU pomocou dvojitého prepojeného zoznamu a hašovania:
- Implementácia vyrovnávacej pamäte LRU pomocou Deque & Hashmap:
- Implementácia vyrovnávacej pamäte LRU pomocou Stack & Hashmap:
- Cache LRU pomocou implementácie Counter:
- Implementácia vyrovnávacej pamäte LRU pomocou Lazy Updates:
- Analýza zložitosti vyrovnávacej pamäte LRU:
- Výhody vyrovnávacej pamäte LRU:
- Nevýhody vyrovnávacej pamäte LRU:
- Aplikácia vyrovnávacej pamäte LRU v reálnom svete:
LRU Algoritmus je štandardný problém a môže mať odchýlky podľa potreby, napríklad v operačných systémoch LRU hrá kľúčovú úlohu, pretože sa dá použiť ako algoritmus na nahradenie stránky, aby sa minimalizovali chyby stránky.
Operácie na vyrovnávacej pamäti LRU:
- LRUCache (kapacita c): Inicializujte vyrovnávaciu pamäť LRU s kapacitou kladnej veľkosti c.
- dostať (kľúč) : Vráti hodnotu kľúča ' k' ak je prítomný vo vyrovnávacej pamäti, inak vráti -1. Aktualizuje tiež prioritu údajov vo vyrovnávacej pamäti LRU.
- vložiť (kľúč, hodnota): Aktualizujte hodnotu kľúča, ak tento kľúč existuje. V opačnom prípade pridajte pár kľúč – hodnota do vyrovnávacej pamäte. Ak počet kľúčov prekročil kapacitu vyrovnávacej pamäte LRU, zrušte kľúč, ktorý ste použili naposledy.
Fungovanie vyrovnávacej pamäte LRU:
Predpokladajme, že máme vyrovnávaciu pamäť LRU s kapacitou 3 a chceli by sme vykonať nasledujúce operácie:
- Vložte (kľúč=1, hodnota=A) do vyrovnávacej pamäte
- Vložte (kľúč=2, hodnota=B) do vyrovnávacej pamäte
- Vložte (kľúč=3, hodnota=C) do vyrovnávacej pamäte
- Získajte (kľúč=2) z vyrovnávacej pamäte
- Získajte (kľúč=4) z vyrovnávacej pamäte
- Vložte (kľúč=4, hodnota=D) do vyrovnávacej pamäte
- Vložte (kľúč=3, hodnota=E) do vyrovnávacej pamäte
- Získajte (kľúč=4) z vyrovnávacej pamäte
- Vložte (kľúč=1, hodnota=A) do vyrovnávacej pamäte
Vyššie uvedené operácie sa vykonávajú jedna po druhej, ako je znázornené na obrázku nižšie:
Podrobné vysvetlenie každej operácie:
- Vložte (kľúč 1, hodnota A) : Keďže vyrovnávacia pamäť LRU má prázdnu kapacitu = 3, nie je potrebná žiadna výmena a na začiatok umiestnime {1 : A}, t. j. {1 : A} má najvyššiu prioritu.
- Vložte (kľúč 2, hodnota B) : Keďže vyrovnávacia pamäť LRU má prázdnu kapacitu=2, opäť nie je potrebná žiadna výmena, ale teraz má {2 : B} najvyššiu prioritu a prioritu zníženia {1 : A}.
- Vložte (kľúč 3, hodnota C) : Vo vyrovnávacej pamäti je stále 1 voľné miesto, preto vložte {3 : C} bez náhrady, všimnite si, že teraz je vyrovnávacia pamäť plná a aktuálne poradie priorít od najvyššej po najnižšiu je {3:C}, {2:B }, {1:A}.
- Získať (kľúč 2) : Teraz vráťte hodnotu kľúča=2 počas tejto operácie, aj keď sa používa kľúč=2, nové poradie priority je teraz {2:B}, {3:C}, {1:A}
- Získajte (kľúč 4): Všimnite si, že kľúč 4 nie je prítomný vo vyrovnávacej pamäti, pre túto operáciu vrátime „-1“.
- Vložte (kľúč 4, hodnota D) : Všimnite si, že vyrovnávacia pamäť je PLNÁ, teraz pomocou algoritmu LRU zistite, ktorý kľúč bol použitý naposledy. Keďže {1:A} malo najmenšiu prioritu, odstráňte {1:A} z našej vyrovnávacej pamäte a vložte {4:D} do vyrovnávacej pamäte. Všimnite si, že nové poradie priority je {4:D}, {2:B}, {3:C}
- Vložte (kľúč 3, hodnota E) : Keďže kľúč=3 bol už prítomný vo vyrovnávacej pamäti s hodnotou=C, táto operácia nebude mať za následok odstránenie žiadneho kľúča, ale aktualizuje hodnotu kľúča=3 na „ AND' . Teraz sa nové poradie priority zmení na {3:E}, {4:D}, {2:B}
- Získať (kľúč 4) : Vráti hodnotu kľúča=4. Teraz sa nová priorita stane {4:D}, {3:E}, {2:B}
- Vložte (kľúč 1, hodnota A) : Keďže naša vyrovnávacia pamäť je PLNÁ, použite náš algoritmus LRU na určenie, ktorý kľúč bol naposledy použitý, a keďže {2:B} mal najmenšiu prioritu, odstráňte {2:B} z našej vyrovnávacej pamäte a vložte {1:A} do cache. Teraz je nové poradie priority {1:A}, {4:D}, {3:E}
Spôsoby implementácie vyrovnávacej pamäte LRU:
LRU cache môže byť implementovaná rôznymi spôsobmi a každý programátor si môže zvoliť iný prístup. Nižšie sú však bežne používané prístupy:
- LRU pomocou fronty a hashovania
- pomocou LRU Dvojito prepojený zoznam + hašovanie
- LRU pomocou Deque
- LRU pomocou zásobníka
- pomocou LRU Implementácia pultu
- LRU pomocou Lazy Updates
Implementácia vyrovnávacej pamäte LRU pomocou frontu a hashovania:
Na implementáciu vyrovnávacej pamäte LRU používame dve dátové štruktúry.
preity zinta
- Fronta sa implementuje pomocou dvojito prepojeného zoznamu. Maximálna veľkosť frontu sa bude rovnať celkovému počtu dostupných snímok (veľkosť vyrovnávacej pamäte). Naposledy použité strany budú blízko prednej strany a najmenej naposledy použité strany budú blízko zadnej strany.
- A Hash s číslom stránky ako kľúčom a adresou zodpovedajúceho uzla frontu ako hodnotou.
Keď sa na stránku odkazuje, požadovaná stránka môže byť v pamäti. Ak je v pamäti, musíme odpojiť uzol zoznamu a priviesť ho do popredia frontu.
Ak požadovaná stránka nie je v pamäti, prenesieme ju do pamäte. Jednoducho povedané, pridáme nový uzol na začiatok frontu a aktualizujeme zodpovedajúcu adresu uzla v hash. Ak je front plný, t. j. všetky rámce sú plné, odstránime uzol zo zadnej časti frontu a nový uzol pridáme do prednej časti frontu.
Ilustrácia:
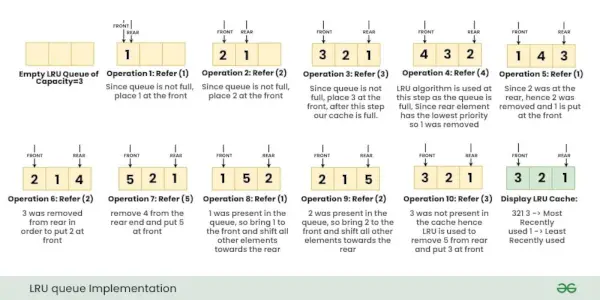
Pozrime sa na operácie, Odkazy kľúč X s vo vyrovnávacej pamäti LRU: { 1, 2, 3, 4, 1, 2, 5, 1, 2, 3 }
Poznámka: Na začiatku nie je v pamäti žiadna stránka.Nižšie uvedené obrázky ukazujú krok za krokom vykonávanie vyššie uvedených operácií na vyrovnávacej pamäti LRU.
Algoritmus:
- Vytvorte triedu LRUCache s deklarovaním zoznamu typu int, neusporiadanej mapy typu
- V referenčnej funkcii LRUCache
- Ak sa táto hodnota nenachádza vo fronte, posuňte túto hodnotu pred front a odstráňte poslednú hodnotu, ak je front plný
- Ak je hodnota už prítomná, odstráňte ju z frontu a zatlačte ju do prednej časti frontu
- V zobrazení funkcie tlače, LRUCache pomocou fronty začínajúce spredu
Nižšie je uvedená implementácia vyššie uvedeného prístupu:
C++
// We can use stl container list as a double> // ended queue to store the cache keys, with> // the descending time of reference from front> // to back and a set container to check presence> // of a key. But to fetch the address of the key> // in the list using find(), it takes O(N) time.> // This can be optimized by storing a reference> // (iterator) to each key in a hash map.> #include> using> namespace> std;> > class> LRUCache {> >// store keys of cache> >list<>int>>dq;> > >// store references of key in cache> >unordered_map<>int>, list<>int>>::iterator> ma;> >int> csize;>// maximum capacity of cache> > public>:> >LRUCache(>int>);> >void> refer(>int>);> >void> display();> };> > // Declare the size> LRUCache::LRUCache(>int> n) { csize = n; }> > // Refers key x with in the LRU cache> void> LRUCache::refer(>int> x)> {> >// not present in cache> >if> (ma.find(x) == ma.end()) {> >// cache is full> >if> (dq.size() == csize) {> >// delete least recently used element> >int> last = dq.back();> > >// Pops the last element> >dq.pop_back();> > >// Erase the last> >ma.erase(last);> >}> >}> > >// present in cache> >else> >dq.erase(ma[x]);> > >// update reference> >dq.push_front(x);> >ma[x] = dq.begin();> }> > // Function to display contents of cache> void> LRUCache::display()> {> > >// Iterate in the deque and print> >// all the elements in it> >for> (>auto> it = dq.begin(); it != dq.end(); it++)> >cout << (*it) <<>' '>;> > >cout << endl;> }> > // Driver Code> int> main()> {> >LRUCache ca(4);> > >ca.refer(1);> >ca.refer(2);> >ca.refer(3);> >ca.refer(1);> >ca.refer(4);> >ca.refer(5);> >ca.display();> > >return> 0;> }> // This code is contributed by Satish Srinivas> |
>
>
C
// A C program to show implementation of LRU cache> #include> #include> > // A Queue Node (Queue is implemented using Doubly Linked> // List)> typedef> struct> QNode {> >struct> QNode *prev, *next;> >unsigned> >pageNumber;>// the page number stored in this QNode> } QNode;> > // A Queue (A FIFO collection of Queue Nodes)> typedef> struct> Queue {> >unsigned count;>// Number of filled frames> >unsigned numberOfFrames;>// total number of frames> >QNode *front, *rear;> } Queue;> > // A hash (Collection of pointers to Queue Nodes)> typedef> struct> Hash {> >int> capacity;>// how many pages can be there> >QNode** array;>// an array of queue nodes> } Hash;> > // A utility function to create a new Queue Node. The queue> // Node will store the given 'pageNumber'> QNode* newQNode(unsigned pageNumber)> {> >// Allocate memory and assign 'pageNumber'> >QNode* temp = (QNode*)>malloc>(>sizeof>(QNode));> >temp->pageNumber = pageNumber;> > >// Initialize prev and next as NULL> >temp->predchádzajúci = temp->ďalší = NULL;> > >return> temp;> }> > // A utility function to create an empty Queue.> // The queue can have at most 'numberOfFrames' nodes> Queue* createQueue(>int> numberOfFrames)> {> >Queue* queue = (Queue*)>malloc>(>sizeof>(Queue));> > >// The queue is empty> >queue->počet = 0;> >queue->predné = front->zadné = NULL;> > >// Number of frames that can be stored in memory> >queue->počet snímok = počet snímok;> > >return> queue;> }> > // A utility function to create an empty Hash of given> // capacity> Hash* createHash(>int> capacity)> {> >// Allocate memory for hash> >Hash* hash = (Hash*)>malloc>(>sizeof>(Hash));> >hash->kapacita = kapacita;> > >// Create an array of pointers for referring queue nodes> >hash->pole> >= (QNode**)>malloc>(hash->kapacita *>sizeof>(QNode*));> > >// Initialize all hash entries as empty> >int> i;> >for> (i = 0; i capacity; ++i)> >hash->pole[i] = NULL;> > >return> hash;> }> > // A function to check if there is slot available in memory> int> AreAllFramesFull(Queue* queue)> {> >return> queue->pocet == fronta->pocetFrame;> }> > // A utility function to check if queue is empty> int> isQueueEmpty(Queue* queue)> {> >return> queue->zadný == NULL;> }> > // A utility function to delete a frame from queue> void> deQueue(Queue* queue)> {> >if> (isQueueEmpty(queue))> >return>;> > >// If this is the only node in list, then change front> >if> (queue->predné == fronta->zadné)> >queue->front = NULL;> > >// Change rear and remove the previous rear> >QNode* temp = queue->zadná časť;> >queue->zadný = front->zadný->predchádzajúci;> > >if> (queue->zadná časť)> >queue->zadný->ďalší = NULL;> > >free>(temp);> > >// decrement the number of full frames by 1> >queue->počítať --;> }> > // A function to add a page with given 'pageNumber' to both> // queue and hash> void> Enqueue(Queue* queue, Hash* hash, unsigned pageNumber)> {> >// If all frames are full, remove the page at the rear> >if> (AreAllFramesFull(queue)) {> >// remove page from hash> >hash->pole[front->zadny->cislo strany] = NULL;> >deQueue(queue);> >}> > >// Create a new node with given page number,> >// And add the new node to the front of queue> >QNode* temp = newQNode(pageNumber);> >temp->ďalší = front->front;> > >// If queue is empty, change both front and rear> >// pointers> >if> (isQueueEmpty(queue))> >queue->zadný = front->front = teplota;> >else> // Else change the front> >{> >queue->predná->predchádzajúca = teplota;> >queue->predná = teplota;> >}> > >// Add page entry to hash also> >hash->pole[číslo stránky] = temp;> > >// increment number of full frames> >queue->počet++;> }> > // This function is called when a page with given> // 'pageNumber' is referenced from cache (or memory). There> // are two cases:> // 1. Frame is not there in memory, we bring it in memory> // and add to the front of queue> // 2. Frame is there in memory, we move the frame to front> // of queue> void> ReferencePage(Queue* queue, Hash* hash,> >unsigned pageNumber)> {> >QNode* reqPage = hash->pole[číslo stránky];> > >// the page is not in cache, bring it> >if> (reqPage == NULL)> >Enqueue(queue, hash, pageNumber);> > >// page is there and not at front, change pointer> >else> if> (reqPage != queue->vpredu) {> >// Unlink rquested page from its current location> >// in queue.> >reqPage->predchádzajúci->ďalší = reqStránka->ďalší;> >if> (reqPage->ďalej)> >reqPage->dalsi->predchadzajuci = reqPage->predch.;> > >// If the requested page is rear, then change rear> >// as this node will be moved to front> >if> (reqPage == queue->zadná časť) {> >queue->zadná strana = reqPage->prev;> >queue->zadný->ďalší = NULL;> >}> > >// Put the requested page before current front> >reqPage->ďalší = front->front;> >reqPage->predchádzajúci = NULL;> > >// Change prev of current front> >reqPage->dalsia->predchadzajuca = reqPage;> > >// Change front to the requested page> >queue->front = reqPage;> >}> }> > // Driver code> int> main()> {> >// Let cache can hold 4 pages> >Queue* q = createQueue(4);> > >// Let 10 different pages can be requested (pages to be> >// referenced are numbered from 0 to 9> >Hash* hash = createHash(10);> > >// Let us refer pages 1, 2, 3, 1, 4, 5> >ReferencePage(q, hash, 1);> >ReferencePage(q, hash, 2);> >ReferencePage(q, hash, 3);> >ReferencePage(q, hash, 1);> >ReferencePage(q, hash, 4);> >ReferencePage(q, hash, 5);> > >// Let us print cache frames after the above referenced> >// pages> >printf>(>'%d '>, q->front->pageNumber);> >printf>(>'%d '>, q->front->next->pageNumber);> >printf>(>'%d '>, q->front->next->next->pageNumber);> >printf>(>'%d '>, q->front->next->next->next->pageNumber);> > >return> 0;> }> |
>
>
char to int java
Java
/* We can use Java inbuilt Deque as a double> >ended queue to store the cache keys, with> >the descending time of reference from front> >to back and a set container to check presence> >of a key. But remove a key from the Deque using> >remove(), it takes O(N) time. This can be> >optimized by storing a reference (iterator) to> >each key in a hash map. */> import> java.util.Deque;> import> java.util.HashSet;> import> java.util.Iterator;> import> java.util.LinkedList;> > public> class> LRUCache {> > >// store keys of cache> >private> Deque doublyQueue;> > >// store references of key in cache> >private> HashSet hashSet;> > >// maximum capacity of cache> >private> final> int> CACHE_SIZE;> > >LRUCache(>int> capacity)> >{> >doublyQueue =>new> LinkedList();> >hashSet =>new> HashSet();> >CACHE_SIZE = capacity;> >}> > >/* Refer the page within the LRU cache */> >public> void> refer(>int> page)> >{> >if> (!hashSet.contains(page)) {> >if> (doublyQueue.size() == CACHE_SIZE) {> >int> last = doublyQueue.removeLast();> >hashSet.remove(last);> >}> >}> >else> {>/* The found page may not be always the last> >element, even if it's an intermediate> >element that needs to be removed and added> >to the start of the Queue */> >doublyQueue.remove(page);> >}> >doublyQueue.push(page);> >hashSet.add(page);> >}> > >// display contents of cache> >public> void> display()> >{> >Iterator itr = doublyQueue.iterator();> >while> (itr.hasNext()) {> >System.out.print(itr.next() +>' '>);> >}> >}> > >// Driver code> >public> static> void> main(String[] args)> >{> >LRUCache cache =>new> LRUCache(>4>);> >cache.refer(>1>);> >cache.refer(>2>);> >cache.refer(>3>);> >cache.refer(>1>);> >cache.refer(>4>);> >cache.refer(>5>);> >cache.display();> >}> }> // This code is contributed by Niraj Kumar> |
>
>
Python3
# We can use stl container list as a double> # ended queue to store the cache keys, with> # the descending time of reference from front> # to back and a set container to check presence> # of a key. But to fetch the address of the key> # in the list using find(), it takes O(N) time.> # This can be optimized by storing a reference> # (iterator) to each key in a hash map.> class> LRUCache:> ># store keys of cache> >def> __init__(>self>, n):> >self>.csize>=> n> >self>.dq>=> []> >self>.ma>=> {}> > > ># Refers key x with in the LRU cache> >def> refer(>self>, x):> > ># not present in cache> >if> x>not> in> self>.ma.keys():> ># cache is full> >if> len>(>self>.dq)>=>=> self>.csize:> ># delete least recently used element> >last>=> self>.dq[>->1>]> > ># Pops the last element> >ele>=> self>.dq.pop();> > ># Erase the last> >del> self>.ma[last]> > ># present in cache> >else>:> >del> self>.dq[>self>.ma[x]]> > ># update reference> >self>.dq.insert(>0>, x)> >self>.ma[x]>=> 0>;> > ># Function to display contents of cache> >def> display(>self>):> > ># Iterate in the deque and print> ># all the elements in it> >print>(>self>.dq)> > # Driver Code> ca>=> LRUCache(>4>)> > ca.refer(>1>)> ca.refer(>2>)> ca.refer(>3>)> ca.refer(>1>)> ca.refer(>4>)> ca.refer(>5>)> ca.display()> # This code is contributed by Satish Srinivas> |
>
>
C#
// C# program to implement the approach> > using> System;> using> System.Collections.Generic;> > class> LRUCache {> >// store keys of cache> >private> List<>int>>doubleQueue;> > >// store references of key in cache> >private> HashSet<>int>>hashSet;> > >// maximum capacity of cache> >private> int> CACHE_SIZE;> > >public> LRUCache(>int> capacity)> >{> >doublyQueue =>new> List<>int>>();> >hashSet =>new> HashSet<>int>>();> >CACHE_SIZE = capacity;> >}> > >/* Refer the page within the LRU cache */> >public> void> Refer(>int> page)> >{> >if> (!hashSet.Contains(page)) {> >if> (doublyQueue.Count == CACHE_SIZE) {> >int> last> >= doublyQueue[doublyQueue.Count - 1];> >doublyQueue.RemoveAt(doublyQueue.Count - 1);> >hashSet.Remove(last);> >}> >}> >else> {> >/* The found page may not be always the last> >element, even if it's an intermediate> >element that needs to be removed and added> >to the start of the Queue */> >doublyQueue.Remove(page);> >}> >doublyQueue.Insert(0, page);> >hashSet.Add(page);> >}> > >// display contents of cache> >public> void> Display()> >{> >foreach>(>int> page>in> doublyQueue)> >{> >Console.Write(page +>' '>);> >}> >}> > >// Driver code> >static> void> Main(>string>[] args)> >{> >LRUCache cache =>new> LRUCache(4);> >cache.Refer(1);> >cache.Refer(2);> >cache.Refer(3);> >cache.Refer(1);> >cache.Refer(4);> >cache.Refer(5);> >cache.Display();> >}> }> > // This code is contributed by phasing17> |
>
>
Javascript
// JS code to implement the approach> class LRUCache {> >constructor(n) {> >this>.csize = n;> >this>.dq = [];> >this>.ma =>new> Map();> >}> > >refer(x) {> >if> (!>this>.ma.has(x)) {> >if> (>this>.dq.length ===>this>.csize) {> >const last =>this>.dq[>this>.dq.length - 1];> >this>.dq.pop();> >this>.ma.>delete>(last);> >}> >}>else> {> >this>.dq.splice(>this>.dq.indexOf(x), 1);> >}> > >this>.dq.unshift(x);> >this>.ma.set(x, 0);> >}> > >display() {> >console.log(>this>.dq);> >}> }> > const cache =>new> LRUCache(4);> > cache.refer(1);> cache.refer(2);> cache.refer(3);> cache.refer(1);> cache.refer(4);> cache.refer(5);> cache.display();> > // This code is contributed by phasing17> |
>
>
Implementácia vyrovnávacej pamäte LRU pomocou dvojitého prepojeného zoznamu a hašovania :
Myšlienka je veľmi základná, t.j. vkladať prvky do hlavy.
- ak sa prvok v zozname nenachádza, pridajte ho na začiatok zoznamu
- ak je prvok prítomný v zozname, presuňte prvok na začiatok a posuňte zostávajúci prvok zoznamu
Všimnite si, že priorita uzla bude závisieť od vzdialenosti tohto uzla od hlavy, čím je uzol najbližšie k hlave, tým vyššiu prioritu má. Takže keď je veľkosť vyrovnávacej pamäte plná a potrebujeme odstrániť nejaký prvok, odstránime prvok susediaci s koncom dvojito prepojeného zoznamu.
Implementácia vyrovnávacej pamäte LRU pomocou Deque & Hashmap:
Štruktúra údajov Deque umožňuje vkladanie a vymazávanie spredu aj z konca, táto vlastnosť umožňuje implementáciu LRU, pretože predný prvok môže predstavovať prvok s vysokou prioritou, zatiaľ čo koncový prvok môže byť prvkom s nízkou prioritou, t. j. Najmenej naposledy použitý.
pracuje:
- Získajte operáciu : Skontroluje, či kľúč existuje v hašovacej mape vyrovnávacej pamäte, a postupujte podľa nasledujúcich prípadov na deque:
- Ak sa nájde kľúč:
- Položka sa považuje za nedávno použitú, preto sa presunie na prednú stranu deque.
- Hodnota spojená s kľúčom sa vráti ako výsledok
get>prevádzka.- Ak sa kľúč nenájde:
- návrat -1 na označenie, že takýto kľúč neexistuje.
- Vložte operáciu: Najprv skontrolujte, či kľúč už existuje v hašovacej mape vyrovnávacej pamäte a postupujte podľa nižšie uvedených prípadov na deque
- Ak kľúč existuje:
- Hodnota spojená s kľúčom sa aktualizuje.
- Položka sa presunie na prednú časť deque, pretože je teraz naposledy použitá.
- Ak kľúč neexistuje:
- Ak je vyrovnávacia pamäť plná, znamená to, že je potrebné vložiť novú položku a najmenej nedávno použitú položku je potrebné odstrániť. To sa robí odstránením položky z konca deque a zodpovedajúcej položky z hash mapy.
- Nový pár kľúč-hodnota sa potom vloží do hašovacej mapy aj na prednú stranu deque, aby znamenal, že ide o naposledy použitú položku
Implementácia vyrovnávacej pamäte LRU pomocou Stack & Hashmap:
Implementácia vyrovnávacej pamäte LRU (Najmenej nedávno použitá) pomocou štruktúry údajov zásobníka a hašovania môže byť trochu zložitejšia, pretože jednoduchý zásobník neposkytuje efektívny prístup k najmenej nedávno použitej položke. Môžete však kombinovať zásobník s hash mapou, aby ste to dosiahli efektívne. Tu je prístup na vysokej úrovni na jeho implementáciu:
- Použite hashovú mapu : Hašovacia mapa bude uchovávať páry kľúč – hodnota vyrovnávacej pamäte. Kľúče sa namapujú na zodpovedajúce uzly v zásobníku.
- Použite zásobník : Zásobník zachová poradie kľúčov na základe ich použitia. Najmenej použitá položka bude v spodnej časti zásobníka a naposledy použitá položka bude v hornej časti
Tento prístup nie je taký efektívny, a preto sa často nepoužíva.
Cache LRU pomocou implementácie Counter:
Každý blok vo vyrovnávacej pamäti bude mať svoj vlastný počítadlo LRU, do ktorého patrí hodnota počítadla {0 až n-1} , tu ' n ‘ predstavuje veľkosť vyrovnávacej pamäte. Blok, ktorý sa zmení pri výmene bloku, sa stane blokom MRU a v dôsledku toho sa jeho hodnota počítadla zmení na n – 1. Hodnoty počítadla väčšie ako hodnota počítadla prístupového bloku sa znížia o jednu. Zvyšné bloky sú nezmenené.
| Hodnota Conter | Priorita | Použitý stav |
|---|---|---|
| 0 | Nízka | Najmenej nedávno použité upraviť súbor linux |
| n-1 | Vysoká | Naposledy používané |
Implementácia vyrovnávacej pamäte LRU pomocou Lazy Updates:
Implementácia vyrovnávacej pamäte LRU (Najmenej nedávno použitá) pomocou lenivých aktualizácií je bežnou technikou na zlepšenie efektívnosti operácií vyrovnávacej pamäte. Lenivé aktualizácie zahŕňajú sledovanie poradia prístupu k položkám bez okamžitej aktualizácie celej štruktúry údajov. Keď dôjde k vynechaniu vyrovnávacej pamäte, môžete sa na základe určitých kritérií rozhodnúť, či vykonáte úplnú aktualizáciu alebo nie.
Analýza zložitosti vyrovnávacej pamäte LRU:
- Časová zložitosť:
- Operácia Put(): O(1) t.j. čas potrebný na vloženie alebo aktualizáciu nového páru kľúč – hodnota je konštantný
- Operácia Get(): O(1) t.j. čas potrebný na získanie hodnoty kľúča je konštantný
- Pomocný priestor: O(N), kde N je kapacita vyrovnávacej pamäte.
Výhody vyrovnávacej pamäte LRU:
- Rýchly prístup : Prístup k údajom z vyrovnávacej pamäte LRU trvá O(1).
- Rýchla aktualizácia : Aktualizácia páru kľúč – hodnota vo vyrovnávacej pamäti LRU trvá O(1).
- Rýchle odstránenie údajov, ktoré boli naposledy použité : Trvá O(1) odstrániť to, čo nebolo nedávno použité.
- Žiadne mlátenie: LRU je v porovnaní s FIFO menej náchylný na mlátenie, pretože zohľadňuje históriu používania stránok. Dokáže zistiť, ktoré stránky sa často používajú, a uprednostniť ich pri prideľovaní pamäte, čím sa zníži počet chýb stránok a diskových I/O operácií.
Nevýhody vyrovnávacej pamäte LRU:
- Vyžaduje veľkú veľkosť vyrovnávacej pamäte na zvýšenie efektívnosti.
- Vyžaduje si to implementáciu dodatočnej dátovej štruktúry.
- Hardvérová pomoc je vysoká.
- V LRU je detekcia chýb v porovnaní s inými algoritmami obtiažna.
- Má obmedzenú prijateľnosť.
Aplikácia vyrovnávacej pamäte LRU v reálnom svete:
- V databázových systémoch pre rýchle výsledky dotazov.
- V operačných systémoch na minimalizáciu chýb stránok.
- Textové editory a IDE na ukladanie často používaných súborov alebo útržkov kódu
- Sieťové smerovače a prepínače využívajú LRU na zvýšenie efektívnosti počítačovej siete
- V optimalizácii kompilátora
- Nástroje na predpovedanie textu a automatické dopĺňanie