Strojové učenie je odvetvím Umela inteligencia ktorá sa zameriava na vývoj modelov a algoritmov, ktoré umožňujú počítačom učiť sa z údajov a zlepšovať sa na základe predchádzajúcich skúseností bez toho, aby boli explicitne naprogramované pre každú úlohu. Jednoducho povedané, ML učí systémy myslieť a chápať ako ľudia učením sa z údajov.
V tomto článku preskúmame rôzne druhy algoritmy strojového učenia ktoré sú dôležité pre budúce požiadavky. Strojové učenie je vo všeobecnosti tréningový systém na poučenie z minulých skúseností a zlepšenie výkonnosti v priebehu času. Strojové učenie pomáha predpovedať obrovské množstvo údajov. Pomáha poskytovať rýchle a presné výsledky, aby ste získali ziskové príležitosti.
Typy strojového učenia
Existuje niekoľko typov strojového učenia, z ktorých každý má špeciálne vlastnosti a aplikácie. Niektoré z hlavných typov algoritmov strojového učenia sú nasledovné:
- Strojové učenie pod dohľadom
- Strojové učenie bez dozoru
- Čiastočne riadené strojové učenie
- Posilňovacie učenie
Typy strojového učenia
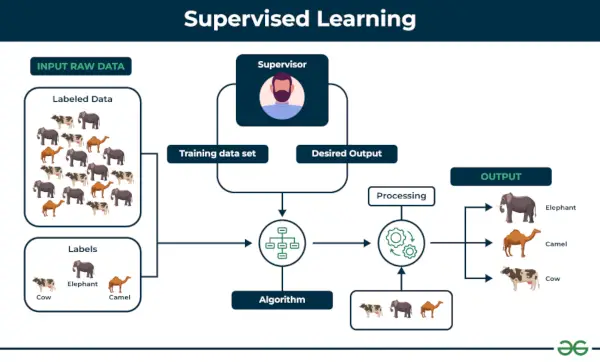
1. Strojové učenie pod dohľadom
Učenie pod dohľadom je definovaný ako keď sa model trénuje na a Označený súbor údajov . Označené množiny údajov majú vstupné aj výstupné parametre. In Učenie pod dohľadom Algoritmy sa učia mapovať body medzi vstupmi a správnymi výstupmi. Má označené školiace aj overovacie súbory údajov.
Učenie pod dohľadom
Poďme to pochopiť pomocou príkladu.
Príklad: Zvážte scenár, v ktorom musíte vytvoriť klasifikátor obrázkov na rozlíšenie medzi mačkami a psami. Ak do algoritmu vložíte súbory údajov o psoch a mačkách s označenými obrázkami, stroj sa z týchto označených obrázkov naučí klasifikovať medzi psom a mačkou. Keď vložíme nové obrázky psa alebo mačky, ktoré ešte nikdy nevidel, použije naučené algoritmy a predpovedá, či ide o psa alebo mačku. To je ako učenie pod dohľadom funguje, a to je najmä klasifikácia obrázkov.
Existujú dve hlavné kategórie vyučovania pod dohľadom, ktoré sú uvedené nižšie:
transformovať reťazec na int
- Klasifikácia
- Regresia
Klasifikácia
Klasifikácia sa zaoberá predpovedaním kategorický cieľové premenné, ktoré predstavujú diskrétne triedy alebo označenia. Napríklad klasifikácia e-mailov ako spam alebo nie, alebo predpovedanie toho, či má pacient vysoké riziko ochorenia srdca. Klasifikačné algoritmy sa učia mapovať vstupné funkcie do jednej z preddefinovaných tried.
Tu sú niektoré klasifikačné algoritmy:
- Logistická regresia
- Podporný vektorový stroj
- Náhodný les
- Rozhodovací strom
- K-Nearest Neighbors (KNN)
- Naivný Bayes
Regresia
Regresia , na druhej strane sa zaoberá predpovedaním nepretržitý cieľových premenných, ktoré predstavujú číselné hodnoty. Napríklad predpovedanie ceny domu na základe jeho veľkosti, polohy a vybavenia alebo predpovedanie predaja produktu. Regresné algoritmy sa učia mapovať vstupné funkcie na súvislú číselnú hodnotu.
previesť int na reťazec v jazyku Java
Tu sú niektoré regresné algoritmy:
- Lineárna regresia
- Polynomiálna regresia
- Ridge Regresia
- Regresia lasa
- Rozhodovací strom
- Náhodný les
Výhody riadeného strojového učenia
- Učenie pod dohľadom modely môžu mať vysokú presnosť, keďže sú na nich trénované označené údaje .
- Proces rozhodovania v modeloch učenia pod dohľadom je často interpretovateľný.
- Často sa dá použiť v predtrénovaných modeloch, čo šetrí čas a zdroje pri vývoji nových modelov od začiatku.
Nevýhody riadeného strojového učenia
- Má obmedzenia v poznaní vzorcov a môže zápasiť s neviditeľnými alebo neočakávanými vzormi, ktoré nie sú prítomné v tréningových údajoch.
- Môže to byť časovo náročné a nákladné, pretože sa na to spolieha označené iba údaje.
- Môže to viesť k slabým zovšeobecneniam na základe nových údajov.
Aplikácie kontrolovaného učenia
Učenie pod dohľadom sa používa v širokej škále aplikácií vrátane:
- Klasifikácia obrázkov : Identifikujte objekty, tváre a ďalšie prvky na obrázkoch.
- Spracovanie prirodzeného jazyka: Extrahujte informácie z textu, ako sú sentiment, entity a vzťahy.
- Rozpoznávanie reči : Prevod hovoreného jazyka na text.
- Systémy odporúčaní : Poskytujte používateľom prispôsobené odporúčania.
- Prediktívna analytika : Predpovedajte výsledky, ako sú predaj, odchod zákazníkov a ceny akcií.
- Lekárska diagnóza : Zistite choroby a iné zdravotné ťažkosti.
- Odhaľovanie podvodov : Identifikujte podvodné transakcie.
- Autonómne vozidlá : Rozpoznať objekty v prostredí a reagovať na ne.
- Detekcia emailového spamu : Klasifikujte e-maily ako spam alebo nie.
- Kontrola kvality vo výrobe : Skontrolujte, či výrobky nemajú chyby.
- Úverové hodnotenie : Posúďte riziko, že dlžník nesplatí pôžičku.
- Hranie : Rozpoznajte postavy, analyzujte správanie hráčov a vytvorte NPC.
- Zákaznícka podpora : Automatizujte úlohy zákazníckej podpory.
- Predpoveď počasia : Vytvárajte predpovede teploty, zrážok a iných meteorologických parametrov.
- Športová analytika : Analyzujte výkon hráčov, predpovedajte hry a optimalizujte stratégie.
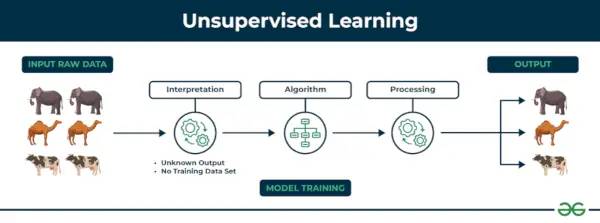
2. Strojové učenie bez dozoru
Učenie bez dozoru Učenie bez dozoru je typ techniky strojového učenia, v ktorom algoritmus objavuje vzory a vzťahy pomocou neoznačených údajov. Na rozdiel od učenia pod dohľadom, učenie bez dozoru nezahŕňa poskytnutie algoritmu s označenými cieľovými výstupmi. Primárnym cieľom učenia bez dozoru je často objavovanie skrytých vzorcov, podobností alebo zhlukov v údajoch, ktoré potom možno použiť na rôzne účely, ako je prieskum údajov, vizualizácia, redukcia rozmerov a ďalšie.
Učenie bez dozoru
Poďme to pochopiť pomocou príkladu.
Príklad: Zvážte, že máte súbor údajov, ktorý obsahuje informácie o nákupoch, ktoré ste uskutočnili v obchode. Prostredníctvom zoskupovania môže algoritmus zoskupiť rovnaké nákupné správanie medzi vami a ostatnými zákazníkmi, čo odhalí potenciálnych zákazníkov bez preddefinovaných označení. Tento typ informácií môže firmám pomôcť získať cieľových zákazníkov, ako aj identifikovať odľahlé hodnoty.
Nižšie sú uvedené dve hlavné kategórie učenia bez dozoru:
- Zhlukovanie
- asociácie
Zhlukovanie
Zhlukovanie je proces zoskupovania údajových bodov do zhlukov na základe ich podobnosti. Táto technika je užitočná na identifikáciu vzorcov a vzťahov v údajoch bez potreby označených príkladov.
Tu sú niektoré zhlukovacie algoritmy:
- Algoritmus klastrovania K-Means
- Algoritmus stredného posunu
- Algoritmus DBSCAN
- Analýza hlavných komponentov
- Nezávislá analýza komponentov
asociácie
Naučte sa pravidlo asociácie ing je technika na zisťovanie vzťahov medzi položkami v súbore údajov. Identifikuje pravidlá, ktoré naznačujú, že prítomnosť jednej položky implikuje prítomnosť inej položky so špecifickou pravdepodobnosťou.
Tu sú niektoré algoritmy učenia sa asociačných pravidiel:
- Apriori algoritmus
- Žiariť
- FP-rastový algoritmus
Výhody strojového učenia bez dozoru
- Pomáha odhaliť skryté vzorce a rôzne vzťahy medzi údajmi.
- Používa sa na úlohy ako napr segmentácia zákazníkov, detekcia anomálií, a prieskum údajov .
- Nevyžaduje označené údaje a znižuje námahu pri označovaní údajov.
Nevýhody strojového učenia bez dozoru
- Bez použitia štítkov môže byť ťažké predpovedať kvalitu výstupu modelu.
- Interpretovateľnosť klastrov nemusí byť jasná a nemusí mať zmysluplné interpretácie.
- Disponuje technikami ako napr automatické kódovače a redukcia rozmerov ktoré možno použiť na extrahovanie zmysluplných funkcií z nespracovaných údajov.
Aplikácie učenia bez dozoru
Tu je niekoľko bežných aplikácií učenia bez dozoru:
- Zhlukovanie : Zoskupte podobné údajové body do zhlukov.
- Detekcia anomálií : Identifikujte odľahlé hodnoty alebo anomálie v údajoch.
- Zníženie rozmerov : Znížte rozmer údajov pri zachovaní základných informácií.
- Systémy odporúčaní : Navrhujte používateľom produkty, filmy alebo obsah na základe ich historického správania alebo preferencií.
- Modelovanie tém : Objavte latentné témy v zbierke dokumentov.
- Odhad hustoty : Odhadnite funkciu hustoty pravdepodobnosti údajov.
- Kompresia obrázkov a videa : Znížte množstvo úložného priestoru potrebného pre multimediálny obsah.
- Predspracovanie údajov : Pomoc s úlohami predbežného spracovania údajov, ako je čistenie údajov, imputácia chýbajúcich hodnôt a škálovanie údajov.
- Analýza trhového koša : Objavte asociácie medzi produktmi.
- Analýza genomických údajov : Identifikujte vzory alebo skupinové gény s podobnými profilmi expresie.
- Segmentácia obrazu : Segmentujte obrázky do zmysluplných oblastí.
- Detekcia komunity v sociálnych sieťach : Identifikujte komunity alebo skupiny jednotlivcov s podobnými záujmami alebo vzťahmi.
- Analýza správania zákazníkov : Odhaľte vzory a poznatky pre lepší marketing a odporúčania produktov.
- Odporúčanie obsahu : Klasifikujte a označujte obsah, aby ste používateľom uľahčili odporúčanie podobných položiek.
- Prieskumná analýza údajov (EDA) : Pred definovaním konkrétnych úloh preskúmajte údaje a získajte prehľad.
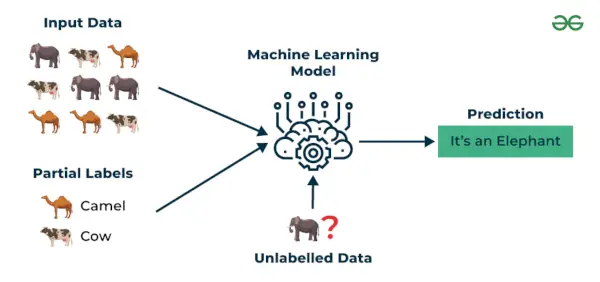
3. Semi-supervised learning
Semi-supervised learning je algoritmus strojového učenia, ktorý funguje medzi pod dohľadom a bez dozoru učenie tak využíva oboje označené a neoznačené údajov. Je to užitočné najmä vtedy, keď je získanie označených údajov nákladné, časovo náročné alebo náročné na zdroje. Tento prístup je užitočný, keď je súbor údajov drahý a časovo náročný. Učenie s čiastočným dohľadom sa vyberá vtedy, keď označené údaje vyžadujú zručnosti a relevantné zdroje na trénovanie alebo učenie sa z nich.
Tieto techniky používame, keď sa zaoberáme údajmi, ktoré sú trochu označené a ich veľká časť je neoznačená. Môžeme použiť techniky bez dozoru na predpovedanie štítkov a potom tieto štítky priviesť k technikám pod dohľadom. Táto technika je väčšinou použiteľná v prípade súborov obrazových údajov, kde zvyčajne nie sú označené všetky obrázky.
zlučovací druh
Semi-supervised learning
Poďme to pochopiť pomocou príkladu.
Príklad : Berte do úvahy, že budujeme model jazykového prekladu. Označenie prekladov pre každý pár viet môže byť náročné na zdroje. Umožňuje modelom učiť sa z označených a neoznačených dvojíc viet, čím sú presnejšie. Táto technika viedla k výraznému zlepšeniu kvality služieb strojového prekladu.
Typy metód učenia s čiastočným dohľadom
Existuje množstvo rôznych metód učenia sa pod dohľadom, pričom každá má svoje vlastné charakteristiky. Niektoré z najbežnejších zahŕňajú:
zoznam fontov v gimp
- Učenie sa čiastočne pod dohľadom pomocou grafov: Tento prístup používa graf na znázornenie vzťahov medzi dátovými bodmi. Graf sa potom použije na šírenie označení z označených dátových bodov do neoznačených dátových bodov.
- Šírenie štítkov: Tento prístup iteratívne šíri značky z označených dátových bodov do neoznačených dátových bodov na základe podobností medzi dátovými bodmi.
- Spoločné školenie: Tento prístup trénuje dva rôzne modely strojového učenia na rôznych podskupinách neoznačených údajov. Tieto dva modely sa potom používajú na vzájomné označenie predpovedí.
- Samotréning: Tento prístup trénuje model strojového učenia na označených údajoch a potom tento model používa na predpovedanie označení pre neoznačené údaje. Model sa potom preškolí na označené údaje a predpovedané označenia pre neoznačené údaje.
- Generatívne adversariálne siete (GAN) : GAN sú typ algoritmu hlbokého učenia, ktorý možno použiť na generovanie syntetických údajov. GAN je možné použiť na generovanie neoznačených údajov pre učenie s čiastočným dohľadom pomocou trénovania dvoch neurónových sietí, generátora a diskriminátora.
Výhody poloriadeného strojového učenia
- Vedie k lepšiemu zovšeobecneniu v porovnaní s učenie pod dohľadom, pretože berie označené aj neoznačené údaje.
- Dá sa použiť na široký rozsah údajov.
Nevýhody poloriadeného strojového učenia
- Polopod dohľadom metódy môžu byť zložitejšie na implementáciu v porovnaní s inými prístupmi.
- Stále si to vyžaduje nejaké označené údaje ktoré nemusia byť vždy dostupné alebo ľahko dostupné.
- Neoznačené údaje môžu zodpovedajúcim spôsobom ovplyvniť výkon modelu.
Aplikácie učenia pod dohľadom
Tu je niekoľko bežných aplikácií učenia s čiastočným dohľadom:
- Klasifikácia obrázkov a rozpoznávanie objektov : Zlepšite presnosť modelov kombináciou malej sady označených obrázkov s väčšou sadou neoznačených obrázkov.
- Spracovanie prirodzeného jazyka (NLP) : Zvýšte výkon jazykových modelov a klasifikátorov kombináciou malej množiny označených textových údajov s obrovským množstvom neoznačeného textu.
- Rozpoznávanie reči: Zlepšite presnosť rozpoznávania reči využitím obmedzeného množstva prepísaných dát reči a rozsiahlejšieho súboru neoznačeného zvuku.
- Systémy odporúčaní : Zlepšite presnosť prispôsobených odporúčaní doplnením riedkeho súboru interakcií medzi používateľmi (označené údaje) množstvom neoznačených údajov o správaní používateľov.
- Zdravotníctvo a lekárske zobrazovanie : Vylepšite analýzu lekárskych snímok využitím malej sady označených lekárskych snímok spolu s väčšou sadou neoznačených snímok.
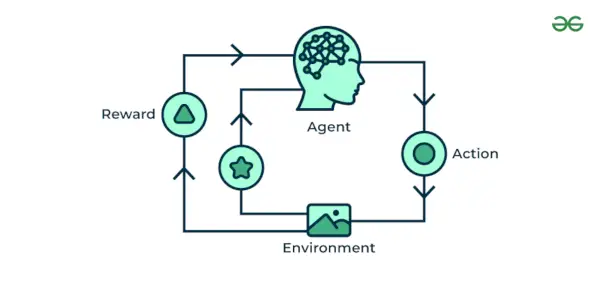
4. Posilňovanie strojového učenia
Posilnenie strojového učenia Algoritmus je metóda učenia, ktorá interaguje s prostredím vytváraním akcií a odhaľovaním chýb. Pokus, omyl a oneskorenie sú najdôležitejšie charakteristiky posilňovacieho učenia. V tejto technike model neustále zvyšuje svoj výkon pomocou spätnej väzby odmeny, aby sa naučil správanie alebo vzor. Tieto algoritmy sú špecifické pre konkrétny problém, napr. Auto s vlastným riadením Google, AlphaGo, kde robot súťaží s ľuďmi a dokonca aj sám so sebou, aby v hre Go získal stále lepších výkonov. Zakaždým, keď vložíme údaje, naučia sa a pridajú údaje k svojim znalostiam, ktorými sú tréningové údaje. Takže čím viac sa naučí, tým lepšie bude vyškolený, a teda aj skúsený.
Tu sú niektoré z najbežnejších algoritmov učenia posilňovania:
- Q-learning: Q-learning je bezmodelový RL algoritmus, ktorý sa učí Q-funkciu, ktorá mapuje stavy na akcie. Funkcia Q odhaduje očakávanú odmenu za vykonanie konkrétnej akcie v danom stave.
- SARSA (Štát-Akcia-Odmena-Štát-Akcia): SARSA je ďalší bezmodelový RL algoritmus, ktorý sa učí Q-funkciu. Na rozdiel od Q-learningu však SARSA aktualizuje Q-funkciu skôr pre akciu, ktorá bola skutočne vykonaná, než pre optimálnu akciu.
- Hlboké Q-učenie : Hlboké Q-learning je kombináciou Q-learningu a hlbokého učenia. Hlboké Q-učenie využíva neurónovú sieť na reprezentáciu funkcie Q, ktorá mu umožňuje naučiť sa zložité vzťahy medzi stavmi a činnosťami.
Posilňovacie strojové učenie
Poďme to pochopiť pomocou príkladov.
Príklad: Zvážte, že trénujete AI agent hrať hru ako šach. Agent skúma rôzne pohyby a na základe výsledku dostáva pozitívnu alebo negatívnu spätnú väzbu. Posilňovacie učenie nachádza aj aplikácie, v ktorých sa učia vykonávať úlohy prostredníctvom interakcie s okolím.
Typy posilňovacieho strojového učenia
Existujú dva hlavné typy posilňovacieho učenia:
Pozitívne posilnenie
linux ktorý
- Odmeňuje agenta za vykonanie požadovanej akcie.
- Povzbudzuje agenta, aby zopakoval správanie.
- Príklady: Podanie maškrty psovi na sedenie, poskytnutie bodu v hre za správnu odpoveď.
Negatívne posilnenie
- Odstraňuje nežiaduci stimul na podporu požadovaného správania.
- Odrádza agenta od opakovania správania.
- Príklady: Vypnutie hlasného bzučiaka pri stlačení páky, vyhnutie sa trestu dokončením úlohy.
Výhody posilňovacieho strojového učenia
- Má autonómne rozhodovanie, ktoré je vhodné pre úlohy a ktoré sa môže naučiť robiť postupnosť rozhodnutí, ako je robotika a hranie hier.
- Táto technika sa uprednostňuje na dosiahnutie dlhodobých výsledkov, ktoré je veľmi ťažké dosiahnuť.
- Používa sa na riešenie zložitých problémov, ktoré nie je možné vyriešiť konvenčnými technikami.
Nevýhody posilňovacieho strojového učenia
- Posilnenie školení Agenti učenia môžu byť výpočtovo nákladní a časovo nároční.
- Posilňovacie učenie nie je vhodnejšie ako riešenie jednoduchých problémov.
- Potrebuje veľa údajov a veľa výpočtov, čo ho robí nepraktickým a nákladným.
Aplikácie strojového učenia výstuže
Tu je niekoľko aplikácií posilňovacieho učenia:
- Hranie hier : RL môže naučiť agentov hrať hry, dokonca aj zložité.
- robotické : RL môže naučiť roboty vykonávať úlohy autonómne.
- Autonómne vozidlá : RL môže pomôcť autonómnym autám pri navigácii a rozhodovaní.
- Systémy odporúčaní : RL môže zlepšiť algoritmy odporúčaní učením sa preferencií používateľov.
- Zdravotná starostlivosť : RL možno použiť na optimalizáciu liečebných plánov a objavovania liekov.
- Spracovanie prirodzeného jazyka (NLP) : RL možno použiť v dialógových systémoch a chatbotoch.
- Financie a obchodovanie : RL možno použiť na algoritmické obchodovanie.
- Riadenie dodávateľského reťazca a zásob : RL možno použiť na optimalizáciu operácií dodávateľského reťazca.
- Energetický manažment : RL možno použiť na optimalizáciu spotreby energie.
- AI hry : RL je možné použiť na vytvorenie inteligentnejších a adaptívnejších NPC vo videohrách.
- Adaptívni osobní asistenti : RL je možné použiť na zlepšenie osobných asistentov.
- Virtuálna realita (VR) a rozšírená realita (AR): RL možno použiť na vytvorenie pohlcujúcich a interaktívnych zážitkov.
- Priemyselná kontrola : RL možno použiť na optimalizáciu priemyselných procesov.
- Vzdelávanie : RL možno použiť na vytvorenie adaptívnych vzdelávacích systémov.
- poľnohospodárstvo : RL možno použiť na optimalizáciu poľnohospodárskych operácií.
Musíte skontrolovať, náš podrobný článok o : Algoritmy strojového učenia
Záver
Na záver, každý typ strojového učenia slúži svojmu vlastnému účelu a prispieva k celkovej úlohe vo vývoji vylepšených schopností predikcie údajov a má potenciál zmeniť rôzne odvetvia, ako napr. Data Science . Pomáha riešiť masívnu produkciu údajov a správu súborov údajov.
Typy strojového učenia – často kladené otázky
1. Akým výzvam čelíte pri učení pod dohľadom?
Niektoré z výziev, s ktorými sa stretávame pri učení pod dohľadom, zahŕňajú najmä riešenie nerovnováhy v triede, vysokokvalitné označené údaje a vyhýbanie sa nadmernému prispôsobeniu, keď modely fungujú zle na údajoch v reálnom čase.
2. Kde môžeme uplatniť učenie pod dohľadom?
Učenie pod dohľadom sa bežne používa pri úlohách, ako je analýza spamových e-mailov, rozpoznávanie obrázkov a analýza sentimentu.
3. Ako vyzerá budúcnosť strojového učenia?
Strojové učenie ako perspektíva budúcnosti môže fungovať v oblastiach, ako je analýza počasia alebo klímy, systémy zdravotnej starostlivosti a autonómne modelovanie.
4. Aké sú rôzne typy strojového učenia?
Existujú tri hlavné typy strojového učenia:
- Učenie pod dohľadom
- Učenie bez dozoru
- Posilňovacie učenie
5. Aké sú najbežnejšie algoritmy strojového učenia?
Niektoré z najbežnejších algoritmov strojového učenia zahŕňajú:
- Lineárna regresia
- Logistická regresia
- Podporné vektorové stroje (SVM)
- K-najbližší susedia (KNN)
- Rozhodovacie stromy
- Náhodné lesy
- Umelé neurónové siete