Kľúčové slovo IDENTITY je vlastnosť v SQL Server. Keď je stĺpec tabuľky definovaný vlastnosťou identity, jeho hodnota bude automaticky vygenerovaná prírastková hodnota . Túto hodnotu vytvára server automaticky. Preto nemôžeme manuálne zadať hodnotu do stĺpca identity ako používateľ. Ak teda označíme stĺpec ako identitu, SQL Server ho naplní spôsobom automatického prírastku.
Syntax
Nasledujú syntaxe na ilustráciu použitia vlastnosti IDENTITY v SQL Server:
IDENTITY[(seed, increment)]
Vyššie uvedené parametre syntaxe sú vysvetlené nižšie:
Poďme pochopiť tento koncept na jednoduchom príklade.
Predpokladajme, že máme ' Študent ' stôl a chceme Študentská karta generovať automaticky. Máme ID začínajúceho študenta 10 a chcete ho zvýšiť o 1 s každým novým ID. V tomto scenári musia byť definované nasledujúce hodnoty.
Semeno: 10
Prírastok: 1
CREATE TABLE Student ( StudentID INT IDENTITY(10, 1) PRIMARY KEY NOT NULL, )
POZNÁMKA: Pre jednu tabuľku na serveri SQL je povolený iba jeden identifikačný stĺpec.
Príklad SQL Server IDENTITY
Poďme pochopiť, ako môžeme použiť vlastnosť identity v tabuľke. Vlastnosť identity v stĺpci možno nastaviť buď pri vytvorení novej tabuľky, alebo po jej vytvorení. Tu uvidíme oba prípady s príkladmi.
Vlastnosť IDENTITY s novou tabuľkou
Nasledujúci príkaz vytvorí novú tabuľku s vlastnosťou identity do zadanej databázy:
CREATE TABLE person ( PersonID INT IDENTITY(10,1) PRIMARY KEY NOT NULL, Fullname VARCHAR(100) NOT NULL, Occupation VARCHAR(50), Gender VARCHAR(10) NOT NULL );
Ďalej do tejto tabuľky vložíme nový riadok s a VÝKON klauzulu na zobrazenie automaticky vygenerovaného ID osoby:
INSERT INTO person(Fullname, Occupation, Gender) OUTPUT inserted.PersonID VALUES('Sara Jackson', 'HR', 'Female');
Po vykonaní tohto dotazu sa zobrazí nasledujúci výstup:
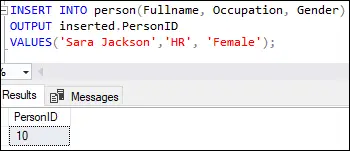
Tento výstup ukazuje, že prvý riadok bol vložený s hodnotou desať v ID osoby ako je uvedené v stĺpci identity definície tabuľky.
Vložíme ďalší riadok do tabuľka osôb ako je uvedené nižšie:
INSERT INTO person(Fullname, Occupation, Gender) OUTPUT inserted.* VALUES('Mark Boucher', 'Cricketer', 'Male'), ('Josh Phillip', 'Writer', 'Male');
Tento dotaz vráti nasledujúci výstup:

Tento výstup ukazuje, že do stĺpca PersonID bol vložený druhý riadok s hodnotou 11 a tretí riadok s hodnotou 12.
Vlastnosť IDENTITY s existujúcou tabuľkou
Tento koncept si vysvetlíme tak, že najprv vymažeme vyššie uvedenú tabuľku a vytvoríme ich bez identity identity. Vykonajte nasledujúci príkaz, aby ste zrušili tabuľku:
DROP TABLE person;
Ďalej vytvoríme tabuľku pomocou nasledujúceho dotazu:
CREATE TABLE person ( Fullname VARCHAR(100) NOT NULL, Occupation VARCHAR(50), Gender VARCHAR(10) NOT NULL );
Ak chceme pridať nový stĺpec s vlastnosťou identity do existujúcej tabuľky, musíme použiť príkaz ALTER. Dotaz nižšie pridá PersonID ako stĺpec identity do tabuľky osôb:
ALTER TABLE person ADD PersonID INT IDENTITY(10,1) PRIMARY KEY NOT NULL;
Explicitné pridanie hodnoty do stĺpca identity
Ak do vyššie uvedenej tabuľky pridáme nový riadok explicitným zadaním hodnoty stĺpca identity, SQL Server vyvolá chybu. Pozrite si nižšie uvedený dotaz:
INSERT INTO person(Fullname, Occupation, Gender, PersonID) VALUES('Mary Smith', 'Business Analyst', 'Female', 13);
Vykonaním tohto dotazu dôjde k nasledujúcej chybe:

Ak chcete explicitne vložiť hodnotu stĺpca identity, musíme najprv nastaviť hodnotu IDENTITY_INSERT na hodnotu ON. Potom vykonajte operáciu vloženia na pridanie nového riadka do tabuľky a potom nastavte hodnotu IDENTITY_INSERT na OFF. Pozrite si nasledujúci kódový skript:
SET IDENTITY_INSERT person ON /*INSERT VALUE*/ INSERT INTO person(Fullname, Occupation, Gender, PersonID) VALUES('Mary Smith', 'Business Analyst', 'Female', 14); SET IDENTITY_INSERT person OFF SELECT * FROM person;
IDENTITY_INSERT ON umožňuje používateľom vkladať údaje do stĺpcov identity IDENTITY_INSERT VYPNUTÉ im bráni pridať hodnotu do tohto stĺpca.
Spustenie kódového skriptu zobrazí nižšie uvedený výstup, kde vidíme, že PersonID s hodnotou 14 bolo vložené úspešne.

Funkcia IDENTITY
SQL Server poskytuje niektoré funkcie identity na prácu so stĺpcami IDENTITY v tabuľke. Tieto funkcie identity sú uvedené nižšie:
- Funkcia @IDENTITY
- Funkcia SCOPE_IDENTITY().
- Funkcia IDENT_CURRENT
- Funkcia IDENTITY
Pozrime sa na funkcie IDENTITY s niekoľkými príkladmi.
Funkcia @IDENTITY
@@IDENTITY je systémom definovaná funkcia, ktorá zobrazí poslednú hodnotu identity (maximálna použitá hodnota identity) vytvorená v tabuľke pre stĺpec IDENTITY v tej istej relácii. Tento stĺpec funkcie vracia hodnotu identity vygenerovanú príkazom po vložení novej položky do tabuľky. Vracia a NULOVÝ hodnotu, keď vykonáme dotaz, ktorý nevytvára hodnoty IDENTITY. Vždy to funguje v rámci aktuálnej relácie. Nedá sa použiť na diaľku.
Príklad
Predpokladajme, že aktuálna maximálna hodnota identity v tabuľke osôb je 13. Teraz pridáme jeden záznam v tej istej relácii, ktorý zvýši hodnotu identity o jeden. Potom použijeme funkciu @@IDENTITY na získanie poslednej hodnoty identity vytvorenej v tej istej relácii.
Tu je úplný skript kódu:
SELECT MAX(PersonID) AS maxidentity FROM person; INSERT INTO person(Fullname, Occupation, Gender) VALUES('Brian Lara', 'Cricket', 'Male'); SELECT @@IDENTITY;
Spustenie skriptu vráti nasledujúci výstup, kde môžeme vidieť, že maximálna použitá hodnota identity je 14.

Funkcia SCOPE_IDENTITY().
SCOPE_IDENTITY() je systémom definovaná funkcia zobraziť najnovšiu hodnotu identity v tabuľke v aktuálnom rozsahu. Tento rozsah môže byť modul, spúšťač, funkcia alebo uložená procedúra. Je podobná funkcii @@IDENTITY(), ibaže táto funkcia má iba obmedzený rozsah. Funkcia SCOPE_IDENTITY vráti hodnotu NULL, ak ju vykonáme pred operáciou vloženia, ktorá vygeneruje hodnotu v rovnakom rozsahu.
Príklad
Nižšie uvedený kód používa funkciu @@IDENTITY aj SCOPE_IDENTITY() v tej istej relácii. Tento príklad najprv zobrazí poslednú hodnotu identity a potom vloží jeden riadok do tabuľky. Ďalej vykoná obe funkcie identity.
SELECT MAX(PersonID) AS maxid FROM person; INSERT INTO person(Fullname, Occupation, Gender) VALUES('Jennifer Winset', 'Actoress', 'Female'); SELECT SCOPE_IDENTITY(); SELECT @@IDENTITY;
Spustenie kódu zobrazí rovnakú hodnotu v aktuálnej relácii a podobnom rozsahu. Pozrite si výstupný obrázok nižšie:

Teraz na príklade uvidíme, ako sa obe funkcie líšia. Najprv vytvoríme dve tabuľky s názvom zamestnanec_data a oddelenie pomocou nižšie uvedeného vyhlásenia:
CREATE TABLE employee_data ( emp_id INT IDENTITY(1, 1) PRIMARY KEY NOT NULL, fullname VARCHAR(20) NULL ) GO CREATE TABLE department ( department_id INT IDENTITY(100, 5) PRIMARY KEY, department_name VARCHAR(20) NULL );
Ďalej vytvoríme spúšťač INSERT v tabuľke zamestnanec_údaje. Tento spúšťač sa vyvolá na vloženie riadku do tabuľky oddelenia vždy, keď vložíme riadok do tabuľky zamestnanec_údaje.
Dotaz nižšie vytvorí spúšťač na vloženie predvolenej hodnoty 'IT' v tabuľke oddelenia pri každom vkladacom dotaze v tabuľke zamestnanec_údaje:
sú to speváci
CREATE TRIGGER Insert_Department ON employee_data FOR INSERT AS BEGIN INSERT INTO department VALUES ('IT') END;
Po vytvorení spúšťača vložíme jeden záznam do tabuľky zamestnanec_data a uvidíme výstup funkcií @@IDENTITY a SCOPE_IDENTITY().
INSERT INTO employee_data VALUES ('John Mathew');
Vykonaním dotazu sa pridá jeden riadok do tabuľky zamestnanec_údaje a v tej istej relácii sa vygeneruje hodnota identity. Po vykonaní dotazu na vloženie v tabuľke zamestnanec_údaje sa automaticky zavolá spúšťač na pridanie jedného riadka do tabuľky oddelenia. Počiatočná hodnota identity je 1 pre zamestnanecké_údaje a 100 pre tabuľku oddelení.
Nakoniec vykonáme nižšie uvedené príkazy, ktoré zobrazia výstup 100 pre funkciu SELECT @@ IDENTITY a 1 pre funkciu SCOPE_IDENTITY, pretože vracajú hodnotu identity len v rovnakom rozsahu.
SELECT MAX(emp_id) FROM employee_data SELECT MAX(department_id) FROM department SELECT @@IDENTITY SELECT SCOPE_IDENTITY()
Tu je výsledok:

Funkcia IDENT_CURRENT().
IDENT_CURRENT je systémom definovaná funkcia zobraziť najnovšiu hodnotu IDENTITY generované pre danú tabuľku pod akýmkoľvek pripojením. Táto funkcia nezohľadňuje rozsah dotazu SQL, ktorý vytvára hodnotu identity. Táto funkcia vyžaduje názov tabuľky, pre ktorú chceme získať hodnotu identity.
Príklad
Pochopíme to tak, že najprv otvoríme dve okná pripojenia. Do prvého okna vložíme jeden záznam, ktorý generuje hodnotu identity 15 v tabuľke osôb. Ďalej môžeme túto hodnotu identity overiť v inom okne pripojenia, kde môžeme vidieť rovnaký výstup. Tu je úplný kód:
1st Connection Window INSERT INTO person(Fullname, Occupation, Gender) VALUES('John Doe', 'Engineer', 'Male'); GO SELECT MAX(PersonID) AS maxid FROM person; 2nd Connection Window SELECT MAX(PersonID) AS maxid FROM person; GO SELECT IDENT_CURRENT('person') AS identity_value;
Vykonaním vyššie uvedených kódov v dvoch rôznych oknách sa zobrazí rovnaká hodnota identity.

Funkcia IDENTITY().
Funkcia IDENTITY() je systémom definovaná funkcia používa sa na vloženie stĺpca identity do novej tabuľky . Táto funkcia sa líši od vlastnosti IDENTITY, ktorú používame s príkazmi CREATE TABLE a ALTER TABLE. Túto funkciu môžeme použiť iba v príkaze SELECT INTO, ktorý sa používa pri prenose údajov z jednej tabuľky do druhej.
Nasledujúca syntax ilustruje použitie tejto funkcie v SQL Server:
IDENTITY (data_type , seed , increment) AS column_name
Ak má zdrojová tabuľka stĺpec IDENTITY, tabuľka vytvorená pomocou príkazu SELECT INTO ho štandardne zdedí. Napríklad , predtým sme vytvorili tabuľku osoba so stĺpcom identity. Predpokladajme, že vytvoríme novú tabuľku, ktorá zdedí tabuľku osôb pomocou príkazov SELECT INTO s funkciou IDENTITY(). V takom prípade dostaneme chybu, pretože zdrojová tabuľka už má stĺpec identity. Pozrite si nižšie uvedený dotaz:
SELECT IDENTITY(INT, 100, 2) AS NEW_ID, PersonID, Fullname, Occupation, Gender INTO person_info FROM person;
Vykonanie vyššie uvedeného príkazu vráti nasledujúce chybové hlásenie:

Poďme vytvoriť novú tabuľku bez identity identity pomocou nižšie uvedeného príkazu:
CREATE TABLE student_data ( roll_no INT PRIMARY KEY NOT NULL, fullname VARCHAR(20) NULL )
Potom skopírujte túto tabuľku pomocou príkazu SELECT INTO vrátane funkcie IDENTITY takto:
SELECT IDENTITY(INT, 100, 1) AS student_id, roll_no, fullname INTO temp_data FROM student_data;
Akonáhle sa príkaz vykoná, môžeme ho overiť pomocou sp_help príkaz, ktorý zobrazí vlastnosti tabuľky.

Môžete vidieť stĺpec IDENTITA v TEMPTABLE vlastnosti podľa stanovených podmienok.
Ak použijeme túto funkciu s príkazom SELECT, SQL Server prejde nasledujúce chybové hlásenie:
Msg 177, Level 15, State 1, Line 2 Funkciu IDENTITY možno použiť len vtedy, keď má príkaz SELECT klauzulu INTO.
Opätovné použitie hodnôt IDENTITY
Nemôžeme opätovne použiť hodnoty identity v tabuľke servera SQL Server. Keď vymažeme ľubovoľný riadok z tabuľky stĺpca identity, v stĺpci identity sa vytvorí medzera. SQL Server tiež vytvorí medzeru, keď vložíme nový riadok do stĺpca identity a príkaz zlyhá alebo sa vráti späť. Medzera znamená, že hodnoty identity sú stratené a nemožno ich znova vygenerovať do stĺpca IDENTITY.
Zvážte nižšie uvedený príklad, aby ste to pochopili prakticky. Už máme tabuľku osôb, ktorá obsahuje nasledujúce údaje:

Ďalej vytvoríme ďalšie dve tabuľky s názvom 'pozícia' a ' osoba_pozícia “ pomocou nasledujúceho vyhlásenia:
CREATE TABLE POSITION ( PositionID INT IDENTITY (1, 1) PRIMARY KEY, Position_name VARCHAR (255) NOT NULL ); CREATE TABLE person_position ( PersonID INT, PositionID INT, PRIMARY KEY (PersonID, PositionID), FOREIGN KEY (PersonID) REFERENCES person (PersonID), FOREIGN KEY (PositionID) REFERENCES POSITION (PositionID) );
Ďalej sa pokúsime vložiť nový záznam do tabuľky osôb a priradiť im pozíciu pridaním nového riadku do tabuľky person_position. Urobíme to pomocou výpisu transakcie, ako je uvedené nižšie:
BEGIN TRANSACTION BEGIN TRY -- insert a new row into the person table INSERT INTO person (Fullname, Occupation, Gender) VALUES('Joan Smith', 'Manager', 'Male'); -- assign a position to a new person INSERT INTO person_position (PersonID, PositionID) VALUES(@@IDENTITY, 10); END TRY BEGIN CATCH IF @@TRANCOUNT > 0 ROLLBACK TRANSACTION; END CATCH IF @@TRANCOUNT > 0 COMMIT TRANSACTION;
Vyššie uvedený skript kódu transakcie úspešne vykoná prvý príkaz vloženia. Ale druhé vyhlásenie zlyhalo, pretože v tabuľke pozícií nebola žiadna pozícia s ID desať. Preto bola celá transakcia vrátená späť.
Keďže maximálna hodnota identity v stĺpci PersonID je 16, prvý príkaz vloženia spotreboval hodnotu identity 17 a potom bola transakcia vrátená späť. Ak teda vložíme ďalší riadok do tabuľky Osoba, ďalšia hodnota identity bude 18. Vykonajte nasledujúci príkaz:
INSERT INTO person(Fullname, Occupation, Gender) VALUES('Peter Drucker',' Writer', 'Female');
Po opätovnom skontrolovaní tabuľky osôb vidíme, že novo pridaný záznam obsahuje hodnotu identity 18.

Dva stĺpce IDENTITY v jednej tabuľke
Technicky nie je možné vytvoriť dva stĺpce identity v jednej tabuľke. Ak to urobíme, SQL Server vyvolá chybu. Pozrite si nasledujúci dotaz:
CREATE TABLE TwoIdentityTable ( ID1 INT IDENTITY (10, 1) NOT NULL, ID2 INT IDENTITY (100, 1) NOT NULL )
Keď spustíme tento kód, uvidíme nasledujúcu chybu:

Pomocou vypočítaného stĺpca však môžeme vytvoriť dva stĺpce identity v jednej tabuľke. Nasledujúci dotaz vytvorí tabuľku s vypočítaným stĺpcom, ktorý používa pôvodný stĺpec identity, a zníži ho o 1.
CREATE TABLE TwoIdentityTable ( ID1 INT IDENTITY (10, 1) NOT NULL, SecondID AS 10000-ID1, Descriptions VARCHAR(60) )
Ďalej do tejto tabuľky pridáme niektoré údaje pomocou nižšie uvedeného príkazu:
INSERT INTO TwoIdentityTable (Descriptions) VALUES ('Javatpoint provides best educational tutorials'), ('www.javatpoint.com')
Nakoniec skontrolujeme údaje tabuľky pomocou príkazu SELECT. Vracia nasledujúci výstup:

Na obrázku môžeme vidieť, ako stĺpec SecondID funguje ako druhý stĺpec identity, pričom sa z počiatočnej hodnoty 9990 znižuje o desať.
Mylné predstavy stĺpca IDENTITY servera SQL Server
Používateľ DBA má veľa mylných predstáv o stĺpcoch identity servera SQL Server. Nasleduje zoznam najbežnejších mylných predstáv týkajúcich sa stĺpcov identity, ktoré by sa mohli zobraziť:
Stĺpec IDENTITY je UNIKÁTNY: Podľa oficiálnej dokumentácie servera SQL Server vlastnosť identity nemôže zaručiť, že hodnota stĺpca je jedinečná. Na vynútenie jedinečnosti stĺpca musíme použiť PRIMARY KEY, UNIQUE obmedzenie alebo UNIQUE index.
Stĺpec IDENTITY generuje po sebe idúce čísla: Oficiálna dokumentácia jasne uvádza, že priradené hodnoty v stĺpci identity sa môžu stratiť pri zlyhaní databázy alebo reštarte servera. Môže to spôsobiť medzery v hodnote identity počas vkladania. Medzera môže vzniknúť aj vtedy, keď vymažeme hodnotu z tabuľky, alebo sa príkaz insert vráti späť. Hodnoty, ktoré vytvárajú medzery, nie je možné ďalej použiť.
Stĺpec IDENTITY nemôže automaticky generovať existujúce hodnoty: Pre stĺpec identity nie je možné automaticky generovať existujúce hodnoty, kým sa vlastnosť identity znova nenasadí pomocou príkazu DBCC CHECKIDENT. Umožňuje nám upraviť počiatočnú hodnotu (počiatočnú hodnotu riadku) vlastnosti identity. Po vykonaní tohto príkazu SQL Server nebude kontrolovať novovytvorené hodnoty, ktoré sa už v tabuľke nachádzajú alebo nie.
Stĺpec IDENTITY ako PRIMÁRNY KĽÚČ stačí na identifikáciu riadku: Ak primárny kľúč obsahuje stĺpec identity v tabuľke bez akýchkoľvek iných jedinečných obmedzení, stĺpec môže ukladať duplicitné hodnoty a zabrániť jedinečnosti stĺpca. Ako vieme, primárny kľúč nemôže ukladať duplicitné hodnoty, ale stĺpec identity môže ukladať duplikáty; odporúča sa nepoužívať primárny kľúč a vlastnosť identity v rovnakom stĺpci.
Použitie nesprávneho nástroja na získanie hodnôt identity späť po vložení: Je tiež bežnou mylnou predstavou o neuvedomení si rozdielov medzi funkciami @@IDENTITY, SCOPE_IDENTITY(), IDENT_CURRENT a IDENTITY() s cieľom získať hodnotu identity priamo vloženú z príkazu, ktorý sme práve vykonali.
Rozdiel medzi SEQUENCE a IDENTITY
Na generovanie automatických čísel používame SEQUENCE aj IDENTITY. Má však určité rozdiely a hlavným rozdielom je, že identita závisí od tabuľky, zatiaľ čo sekvencia nie. Zhrňme ich rozdiely do tabuľkovej formy:
| IDENTITA | SEKVENCIA |
|---|---|
| Vlastnosť identity sa používa pre konkrétnu tabuľku a nemožno ju zdieľať s inými tabuľkami. | DBA definuje sekvenčný objekt, ktorý možno zdieľať medzi viacerými tabuľkami, pretože je nezávislý od tabuľky. |
| Táto vlastnosť automaticky generuje hodnoty vždy, keď sa v tabuľke vykoná príkaz insert. | Používa klauzulu NEXT VALUE FOR na vygenerovanie ďalšej hodnoty pre objekt sekvencie. |
| SQL Server neresetuje hodnotu stĺpca vlastnosti identity na počiatočnú hodnotu. | SQL Server môže obnoviť hodnotu pre objekt sekvencie. |
| Nemôžeme nastaviť maximálnu hodnotu pre vlastnosť identity. | Pre objekt sekvencie môžeme nastaviť maximálnu hodnotu. |
| Je predstavený v SQL Server 2000. | Je predstavený v SQL Server 2012. |
| Táto vlastnosť nemôže generovať hodnotu identity v zostupnom poradí. | Môže generovať hodnoty v klesajúcom poradí. |
Záver
Tento článok poskytne úplný prehľad o vlastnosti IDENTITY v SQL Server. Tu sme sa naučili, ako a kedy sa používa vlastnosť identity, jej rôzne funkcie, mylné predstavy a ako sa líši od postupnosti.