Vyhlásenie GROUP BY v SQL slúži na usporiadanie identických údajov do skupín pomocou niektorých funkcií. t.j. ak má konkrétny stĺpec rovnaké hodnoty v rôznych riadkoch, usporiada tieto riadky do skupiny.
Vlastnosti
- Klauzula GROUP BY sa používa s príkazom SELECT.
- V dotaze je klauzula GROUP BY umiestnená za KDE doložka.
- V dotaze je klauzula GROUP BY umiestnená pred OBJEDNAŤ doložka BY, ak sa použije.
- V dotaze je klauzula Group BY umiestnená pred klauzulou Having.
- Umiestnite podmienku do klauzuly s .
Syntax :
SELECT stĺpec1, názov_funkcie(stĺpec2)
FROM table_name
KDE podmienka
GROUP BY stĺpec1, stĺpec2
ORDER BY stĺpec1, stĺpec2;
prepínač strojopisu
Vysvetlenie:
- názov_funkcie : Názov použitej funkcie, napríklad SUM() , AVG().
- názov_tabuľky : Názov tabuľky.
- stave : Použitý stav.
Predpokladajme, že máme dve tabuľky Zamestnanec a Študent Vzorová tabuľka je nasledovná po pridaní dvoch tabuliek vykonáme niekoľko špecifických operácií, aby sme sa dozvedeli o GROUP BY.
Tabuľka zamestnancov:
CREATE TABLE emp ( emp_no INT PRIMARY KEY, name VARCHAR(50), sal DECIMAL(10,2), age INT );>
Vložte nejaké náhodné údaje do tabuľky a potom vykonáme niekoľko operácií v GROUP BY.
bash spánok
Dopyt:
INSERT INTO emp (emp_no, name, sal, age) VALUES (1, 'Aarav', 50000.00, 25), (2, 'Aditi', 60000.50, 30), (3, 'Amit', 75000.75, 35), (4, 'Anjali', 45000.25, 28), (5, 'Chetan', 80000.00, 32), (6, 'Divya', 65000.00, 27), (7, 'Gaurav', 55000.50, 29), (8, 'Isha', 72000.75, 31), (9, 'Kavita', 48000.25, 26), (10, 'Mohan', 83000.00, 33);>
Výkon:
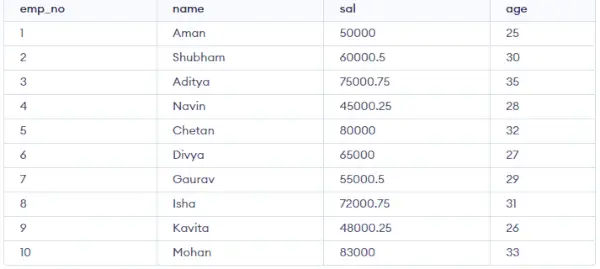
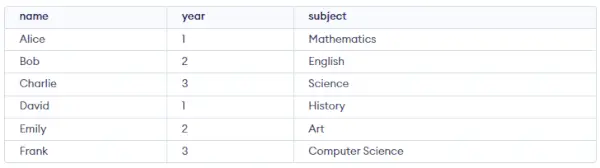
Študentský stôl:
Dopyt:
CREATE TABLE student ( name VARCHAR(50), year INT, subject VARCHAR(50) ); INSERT INTO student (name, year, subject) VALUES ('Alice', 1, 'Mathematics'), ('Bob', 2, 'English'), ('Charlie', 3, 'Science'), ('David', 1, 'History'), ('Emily', 2, 'Art'), ('Frank', 3, 'Computer Science');> Výkon:
Zoskupiť podľa jedného stĺpca
Zoskupiť podľa jedného stĺpca znamená umiestniť všetky riadky s rovnakou hodnotou len v danom stĺpci do jednej skupiny. Zvážte dopyt, ako je uvedené nižšie:
tvrdá väzba vs brožovaná väzba
Dopyt:
SELECT NAME, SUM(SALARY) FROM emp GROUP BY NAME;>
Vyššie uvedený dotaz vytvorí nasledujúci výstup:
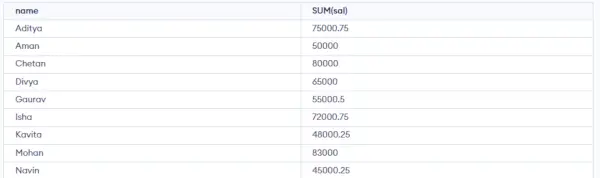
Ako môžete vidieť vo vyššie uvedenom výstupe, riadky s duplicitnými MENAMI sú zoskupené pod rovnakým MENO a ich zodpovedajúci PLAT je súčtom PLATOV duplicitných riadkov. Na výpočet súčtu sa tu používa funkcia SUM() jazyka SQL.
Zoskupiť podľa viacerých stĺpcov
Zoskupiť podľa viacerých stĺpcov je povedzme napr. GROUP BY stĺpec1, stĺpec2 . To znamená umiestniť všetky riadky s rovnakými hodnotami stĺpcov stĺpec 1 a stĺpec 2 v jednej skupine. Zvážte nasledujúci dotaz:
Dopyt:
SELECT SUBJECT, YEAR, Count(*) FROM Student GROUP BY SUBJECT, YEAR;>
Výkon:
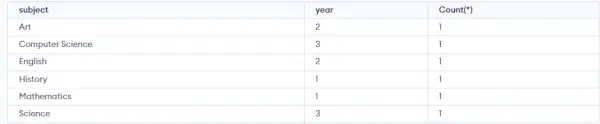
Výkon : Ako môžete vidieť vo vyššie uvedenom výstupe, študenti s rovnakým PREDMETOM aj ROKOM sú umiestnení do rovnakej skupiny. A tí, ktorých jediný PREDMET je rovnaký, ale nie ROK, patria do rôznych skupín. Takže tu sme tabuľku zoskupili podľa dvoch stĺpcov alebo viacerých stĺpcov.
Klauzula HAVING v klauzule GROUP BY
Vieme, že klauzula WHERE sa používa na umiestnenie podmienok na stĺpce, ale čo ak chceme umiestniť podmienky na skupiny? Tu sa používa klauzula HAVING. Môžeme použiť klauzulu HAVING na umiestnenie podmienok na rozhodnutie, ktorá skupina bude súčasťou konečného súboru výsledkov. Taktiež nemôžeme použiť agregačné funkcie ako SUM(), COUNT() atď. s klauzulou WHERE. Ak teda chceme v podmienkach použiť niektorú z týchto funkcií, musíme použiť klauzulu HAVING.
Syntax :
otázky na pohovor v jazyku java
SELECT stĺpec1, názov_funkcie(stĺpec2)
FROM table_name
KDE podmienka
singleton dizajnGROUP BY stĺpec1, stĺpec2
MAJÚ PODMIENKY
ORDER BY stĺpec1, stĺpec2;
Vysvetlenie:
- názov_funkcie : Názov použitej funkcie, napríklad SUM() , AVG().
- názov_tabuľky : Názov tabuľky.
- stave : Použitý stav.
Príklad :
SELECT NAME, SUM(sal) FROM Emp GROUP BY name HAVING SUM(sal)>3000;>
Výkon :
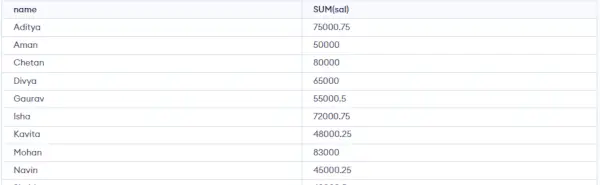
Ako môžete vidieť vo vyššie uvedenom výstupe, iba jedna skupina z troch skupín sa objaví v sade výsledkov, pretože je to jediná skupina, kde je súčet MLATU väčší ako 3000. Použili sme teda klauzulu HAVING, aby sme túto podmienku umiestnili ako Podmienka musí byť umiestnená v skupinách, nie v stĺpcoch.