pandy dataframe.corr() sa používa na nájdenie párovej korelácie všetkých stĺpcov v dátovom rámci Pandas v Pythone. akýkoľvek NaN hodnoty sú automaticky vylúčené. Ak chcete ignorovať akékoľvek nečíselné hodnoty, použite parameter numeric_only = True. V tomto článku sa dozvieme o metóde DataFrame.corr() v Python .
Syntax metódy Pandas DataFrame corr().
Syntax: DataFrame.corr(self, method=’pearson’, min_periods=1, numeric_only = False)
Parametre:
- metóda:
- pearson: štandardný korelačný koeficient
- kendall: Kendall Tau korelačný koeficient
- kopijník: Korelácia hodnosti kopijníka
- min_periods : Minimálny počet pozorovaní požadovaných na jeden pár stĺpcov, aby bol výsledok platný. Momentálne je k dispozícii iba pre koreláciu pearson a spearman
- numeric_only : Či sa má pracovať iba s číselnými hodnotami alebo nie. Predvolene je nastavená na hodnotu False.
Vrátenie: count :y : DataFrame
Metóda korelácií údajov Pandas corr().
Dobrá korelácia závisí od použitia, ale je bezpečné povedať, že máte aspoň 0,6 (alebo -0,6), aby ste to nazvali dobrou koreláciou. Jednoduchý príklad, ktorý ukazuje, ako funguje korelácia Python .
Python3
powershell viacriadkový komentár
import> pandas as pd> df>=> {> >'Array_1'>: [>30>,>70>,>100>],> >'Array_2'>: [>65.1>,>49.50>,>30.7>]> }> data>=> pd.DataFrame(df)> print>(data.corr())> |
>
>
Výkon
Array_1 Array_2 Array_1 1.000000 -0.990773 Array_2 -0.990773 1.000000>
Vytvorenie vzorového dátového rámca
Tlač prvých 10 riadkov dátového rámca.
Poznámka: Korelácia premennej so sebou samým je 1. Pre odkaz na súbor CSV použitý v kóde kliknite tu
Python3
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # Printing the first 10 rows of the data frame for visualization> df[:>10>]> |
>
unsigned int c programovanie
>
Výkon

Príklady metódy Python Pandas DataFrame corr().
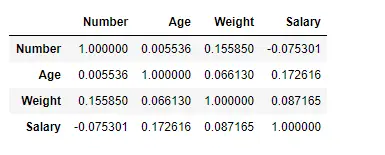
Nájdite koreláciu medzi stĺpcami pomocou pearsonovej metódy
Tu používame funkciu corr () na nájdenie korelácie medzi stĺpcami v dátovom rámci pomocou metódy „Pearson“. V dátovom rámci máme iba štyri číselné stĺpce. Výstupný Dataframe možno interpretovať ako pre ľubovoľnú bunku, korelácia riadkovej premennej so stĺpcovou premennou je hodnota bunky. Ako už bolo spomenuté, korelácia premennej so sebou samým je 1. Z tohto dôvodu sú všetky hodnoty uhlopriečky 1,00.
Python3
# To find the correlation among> # the columns using pearson method> df.corr(method>=>'pearson'>)> |
>
>
Výkon
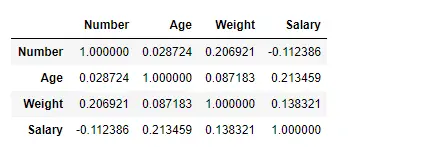
Nájdite koreláciu medzi stĺpcami pomocou metódy Kendall
Použite funkciu Pandas df.corr() na nájdenie korelácie medzi stĺpcami v dátovom rámci pomocou metódy „kendall“. Výstupný Dataframe možno interpretovať ako pre ľubovoľnú bunku, korelácia riadkovej premennej so stĺpcovou premennou je hodnota bunky. Ako už bolo spomenuté, korelácia premennej so sebou samým je 1. Z tohto dôvodu sú všetky hodnoty uhlopriečky 1,00.
Python3
Spojené štáty americké koľko miest
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # To find the correlation among> # the columns using kendall method> df.corr(method>=>'kendall'>)> |
>
>
Výkon