V reálnom svete nie všetky údaje, na ktorých pracujeme, majú cieľovú premennú. Tento druh údajov nemožno analyzovať pomocou algoritmov učenia pod dohľadom. Potrebujeme pomoc bez dozoru algoritmov. Jedným z najpopulárnejších typov analýzy pri učení bez dozoru je segmentácia zákazníkov pre cielené reklamy alebo pri medicínskom zobrazovaní na nájdenie neznámych alebo nových infikovaných oblastí a mnoho ďalších prípadov použitia, o ktorých budeme ďalej diskutovať v tomto článku.
Obsah
- Čo je klastrovanie?
- Typy klastrovania
- Využitie klastrovania
- Typy klastrovacích algoritmov
- Aplikácie klastrovania v rôznych oblastiach:
- Často kladené otázky (FAQ) o klastrovaní
Čo je klastrovanie?
Úloha zoskupovania údajových bodov na základe ich vzájomnej podobnosti sa nazýva klastrovanie alebo klastrová analýza. Táto metóda je definovaná pod vetvou Učenie bez dozoru , ktorej cieľom je získať prehľad z neoznačených údajových bodov, teda na rozdiel od nich učenie pod dohľadom nemáme cieľovú premennú.
Klastrovanie sa zameriava na vytváranie skupín homogénnych údajových bodov z heterogénneho súboru údajov. Vyhodnocuje podobnosť na základe metriky, ako je euklidovská vzdialenosť, kosínusová podobnosť, vzdialenosť na Manhattane atď., a potom zoskupuje body s najvyšším skóre podobnosti.
Napríklad v nižšie uvedenom grafe jasne vidíme, že existujú 3 kruhové zhluky, ktoré sa tvoria na základe vzdialenosti.
java analyzovať reťazec na int
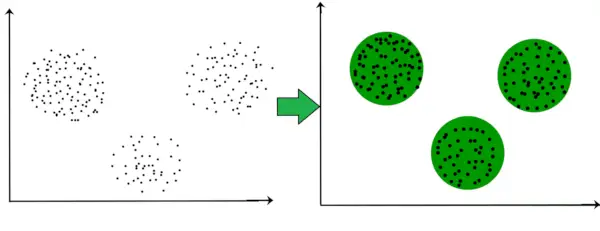
Teraz už nie je nutné, aby vytvorené zhluky mali kruhový tvar. Tvar zhlukov môže byť ľubovoľný. Existuje mnoho algoritmov, ktoré dobre fungujú pri detekcii zhlukov ľubovoľného tvaru.
sú replace
Napríklad v nižšie uvedenom grafe môžeme vidieť, že vytvorené zhluky nemajú kruhový tvar.

Typy klastrovania
Vo všeobecnosti existujú 2 typy klastrovania, ktoré možno vykonať na zoskupenie podobných údajových bodov:
- Tvrdé klastrovanie: Pri tomto type klastrovania každý údajový bod patrí do klastra úplne alebo nie. Povedzme napríklad, že existujú 4 dátové body a musíme ich zoskupiť do 2 zhlukov. Takže každý údajový bod bude patriť do klastra 1 alebo klastra 2.
| Dátové body | Zhluky |
|---|---|
| A | C1 |
| B | C2 |
| C | C2 |
| D | C1 |
- Mäkké zhlukovanie: Pri tomto type klastrovania sa namiesto priradenia každého dátového bodu do samostatného klastra vyhodnocuje pravdepodobnosť alebo pravdepodobnosť, že daný bod je tým klastrom. Povedzme napríklad, že existujú 4 dátové body a musíme ich zoskupiť do 2 zhlukov. Budeme teda vyhodnocovať pravdepodobnosť, že dátový bod patrí do oboch klastrov. Táto pravdepodobnosť sa vypočíta pre všetky dátové body.
| Dátové body | Pravdepodobnosť C1 | Pravdepodobnosť C2 |
| A | 0,91 | 0,09 |
| B | 0,3 | 0,7 |
| C | 0,17 | 0,83 |
| D | 1 | 0 |
Využitie klastrovania
Predtým, ako začneme s typmi klastrovacích algoritmov, prejdeme si prípady použitia klastrovacích algoritmov. Klastrovacie algoritmy sa používajú hlavne na:
- Segmentácia trhu – Firmy využívajú klastrovanie na zoskupovanie svojich zákazníkov a využívajú cielené reklamy na prilákanie väčšieho počtu divákov.
- Analýza sociálnych sietí – Stránky sociálnych médií používajú vaše údaje na pochopenie vášho správania pri prehliadaní a poskytujú vám cielené odporúčania priateľov alebo odporúčania obsahu.
- Lekárske zobrazovanie – Lekári používajú Clustering na zistenie chorých oblastí na diagnostických snímkach, ako sú röntgenové lúče.
- Detekcia anomálií – Na nájdenie odľahlých hodnôt v prúde súboru údajov v reálnom čase alebo na predpovedanie podvodných transakcií môžeme použiť klastrovanie na ich identifikáciu.
- Zjednodušte prácu s veľkými množinami údajov – každý klaster dostane po dokončení klastrovania ID klastra. Teraz môžete zredukovať celú sadu funkcií na jej klastrové ID. Klastrovanie je efektívne, keď môže predstavovať komplikovaný prípad s jednoduchým ID klastra. Pomocou rovnakého princípu môže klastrovanie údajov zjednodušiť zložité súbory údajov.
Existuje oveľa viac prípadov použitia klastrovania, ale existujú niektoré z hlavných a bežných prípadov použitia klastrovania. V budúcnosti budeme diskutovať o klastrovacích algoritmoch, ktoré vám pomôžu vykonávať vyššie uvedené úlohy.
Typy klastrovacích algoritmov
Na povrchovej úrovni pomáha klastrovanie pri analýze neštruktúrovaných údajov. Grafy, najkratšia vzdialenosť a hustota údajových bodov sú niektoré z prvkov, ktoré ovplyvňujú tvorbu zhlukov. Klastrovanie je proces určovania príbuznosti objektov na základe metriky nazývanej miera podobnosti. Metriky podobnosti sa dajú ľahšie nájsť v menších súboroch funkcií. S rastúcim počtom funkcií je čoraz ťažšie vytvárať miery podobnosti. V závislosti od typu klastrovacieho algoritmu, ktorý sa používa pri dolovaní údajov, sa na zoskupovanie údajov zo súborov údajov používa niekoľko techník. V tejto časti sú popísané techniky klastrovania. Rôzne typy zhlukových algoritmov sú:
xampp alternatíva
- Klastrovanie založené na centroidoch (metódy rozdeľovania)
- Zhlukovanie na základe hustoty (metódy založené na modeli)
- Klastrovanie založené na konektivite (hierarchické zoskupovanie)
- Klastrovanie založené na distribúcii
V krátkosti si prejdeme každý z týchto typov.
1. Rozdeľovacie metódy sú najjednoduchšie klastrovacie algoritmy. Zoskupujú dátové body na základe ich blízkosti. Vo všeobecnosti sú mierou podobnosti zvolenou pre tieto algoritmy Euklidovská vzdialenosť, Manhattanská vzdialenosť alebo Minkowského vzdialenosť. Množiny údajov sú rozdelené do vopred určeného počtu klastrov a na každý klaster odkazuje vektor hodnôt. V porovnaní s vektorovou hodnotou nevykazuje premenná vstupných údajov žiadny rozdiel a spája sa s klastrom.
Primárnou nevýhodou týchto algoritmov je požiadavka, aby sme určili počet klastrov, k, buď intuitívne alebo vedecky (pomocou metódy Elbow) predtým, ako akýkoľvek klastrovací systém strojového učenia začne prideľovať dátové body. Napriek tomu je stále najpopulárnejším typom klastrovania. K-znamená a K-medoidov klastrovanie sú niektoré príklady tohto typu klastrovania.
gigabajt vs megabajt
2. Zhlukovanie na základe hustoty (metódy založené na modeli)
Zhlukovanie založené na hustote, metóda založená na modeli, nájde skupiny na základe hustoty údajových bodov. Na rozdiel od klastrovania založeného na centroidoch, ktoré vyžaduje, aby bol počet klastrov vopred definovaný a je citlivý na inicializáciu, zhlukovanie založené na hustote určuje počet klastrov automaticky a je menej náchylné na počiatočné pozície. Sú skvelé pri manipulácii s klastrami rôznych veľkostí a foriem, vďaka čomu sú ideálne pre množiny údajov s nepravidelne tvarovanými alebo prekrývajúcimi sa klastrami. Tieto metódy spravujú oblasti s hustými aj riedkymi údajmi so zameraním na lokálnu hustotu a dokážu rozlíšiť zhluky s rôznymi morfológiami.
Naproti tomu zoskupenie založené na centroidoch, podobne ako k-means, má problém nájsť zhluky ľubovoľného tvaru. Vďaka prednastavenému počtu požiadaviek na klaster a extrémnej citlivosti na počiatočné umiestnenie ťažísk sa výsledky môžu líšiť. Okrem toho tendencia prístupov založených na centroidoch vytvárať sférické alebo konvexné zhluky obmedzuje ich schopnosť zvládnuť komplikované alebo nepravidelne tvarované zhluky. Na záver, zhlukovanie založené na hustote prekonáva nevýhody techník založených na centroidoch tým, že autonómne vyberá veľkosti klastrov, je odolné voči inicializácii a úspešne zachytáva klastre rôznych veľkostí a foriem. Najpopulárnejší zhlukovací algoritmus založený na hustote je DBSCAN .
3. Klastrovanie založené na konektivite (hierarchické zoskupovanie)
Metóda na zostavovanie súvisiacich dátových bodov do hierarchických zhlukov sa nazýva hierarchické zhlukovanie. Každý údajový bod sa na začiatku berie do úvahy ako samostatný klaster, ktorý sa následne skombinuje s klastrami, ktoré sú si najpodobnejšie, aby sa vytvoril jeden veľký klaster, ktorý obsahuje všetky údajové body.
Zamyslite sa nad tým, ako môžete usporiadať zbierku predmetov podľa toho, nakoľko sú si podobné. Každý objekt začína ako svoj vlastný zhluk na báze stromu pri použití hierarchického zhlukovania, ktoré vytvára dendrogram, štruktúru podobnú stromu. Najbližšie páry zhlukov sa potom skombinujú do väčších zhlukov po tom, čo algoritmus preskúma, nakoľko sú si objekty navzájom podobné. Keď je každý objekt v jednom klastri na vrchole stromu, proces spájania sa skončil. Skúmanie rôznych úrovní podrobnosti je jednou zo zábavných vecí na hierarchickom zoskupovaní. Ak chcete získať daný počet zhlukov, môžete vybrať možnosť rezu dendrogram v určitej výške. Čím sú si dva objekty v zhluku podobnejšie, tým sú bližšie. Je to porovnateľné s klasifikáciou položiek podľa ich rodokmeňov, kde sú najbližší príbuzní zoskupení a širšie vetvy znamenajú všeobecnejšie spojenia. Existujú 2 prístupy pre hierarchické zoskupovanie:
- Divisive Clustering : Nasleduje prístup zhora nadol, tu považujeme všetky dátové body za časť jedného veľkého klastra a potom sa tento klaster rozdelí na menšie skupiny.
- Aglomeratívne klastrovanie : Nasleduje prístup zdola nahor, tu považujeme všetky dátové body za súčasť jednotlivých klastrov a potom sa tieto klastre spoja, aby vytvorili jeden veľký klaster so všetkými dátovými bodmi.
4. Klastrovanie založené na distribúcii
Pomocou klastrovania založeného na distribúcii sú dátové body generované a organizované podľa ich sklonu spadať do rovnakého rozdelenia pravdepodobnosti (ako je gaussovské, binomické alebo iné) v rámci údajov. Prvky údajov sú zoskupené pomocou rozdelenia založeného na pravdepodobnosti, ktoré je založené na štatistických rozdeleniach. Zahrnuté sú dátové objekty, ktoré majú vyššiu pravdepodobnosť, že budú v klastri. Je menej pravdepodobné, že dátový bod bude zahrnutý do klastra, čím ďalej je od centrálneho bodu klastra, ktorý existuje v každom klastri.
Významnou nevýhodou prístupov založených na hustote a hraniciach je potreba a priori špecifikovať klastre pre niektoré algoritmy a predovšetkým definícia klastrovej formy pre väčšinu algoritmov. Musí byť vybraté aspoň jedno ladenie alebo hyperparameter, pričom by to malo byť jednoduché, nesprávne nastavenie môže mať neočakávané následky. Klastrovanie založené na distribúcii má jednoznačnú výhodu oproti prístupom zhlukovania založeným na blízkosti a centroidoch, pokiaľ ide o flexibilitu, presnosť a štruktúru zhlukov. Kľúčovou otázkou je, aby sa zabránilo nadmerná montáž Mnoho metód klastrovania pracuje iba so simulovanými alebo vyrobenými údajmi, alebo keď väčšina údajových bodov určite patrí do prednastavenej distribúcie. Najpopulárnejší klastrovací algoritmus založený na distribúcii je Gaussov model zmesi .
Aplikácie klastrovania v rôznych oblastiach:
- marketing: Môže sa použiť na charakterizáciu a objavovanie segmentov zákazníkov na marketingové účely.
- biológia: Môže sa použiť na klasifikáciu medzi rôznymi druhmi rastlín a živočíchov.
- Knižnice: Používa sa pri zoskupovaní rôznych kníh na základe tém a informácií.
- poistenie: Používa sa na uznanie zákazníkov, ich politiky a identifikáciu podvodov.
- Plánovanie mesta: Používa sa na vytváranie skupín domov a na štúdium ich hodnôt na základe ich geografickej polohy a iných prítomných faktorov.
- Štúdie zemetrasení: Poznaním oblastí postihnutých zemetrasením môžeme určiť nebezpečné zóny.
- Spracovanie obrazu : Klastrovanie možno použiť na zoskupenie podobných obrázkov, klasifikáciu obrázkov na základe obsahu a identifikáciu vzorov v obrazových údajoch.
- genetika: Klastrovanie sa používa na zoskupovanie génov, ktoré majú podobné vzorce expresie, a na identifikáciu génových sietí, ktoré spolupracujú v biologických procesoch.
- Financie: Klastrovanie sa používa na identifikáciu trhových segmentov na základe správania zákazníkov, identifikáciu vzorcov v údajoch o akciovom trhu a analýzu rizika v investičných portfóliách.
- Zákaznícky servis: Klastrovanie sa používa na zoskupovanie otázok a sťažností zákazníkov do kategórií, identifikáciu bežných problémov a vývoj cielených riešení.
- Výroba : Klastrovanie sa používa na zoskupovanie podobných produktov, optimalizáciu výrobných procesov a identifikáciu chýb vo výrobných procesoch.
- Lekárska diagnóza: Klastrovanie sa používa na zoskupovanie pacientov s podobnými symptómami alebo chorobami, čo pomáha pri presnej diagnóze a identifikácii účinnej liečby.
- Detekcia podvodu: Klastrovanie sa používa na identifikáciu podozrivých vzorcov alebo anomálií vo finančných transakciách, čo môže pomôcť pri odhaľovaní podvodov alebo iných finančných trestných činov.
- Analýza návštevnosti: Klastrovanie sa používa na zoskupovanie podobných vzorov dopravných údajov, ako sú hodiny v špičke, trasy a rýchlosti, čo môže pomôcť pri zlepšovaní plánovania dopravy a infraštruktúry.
- Analýza sociálnych sietí: Klastrovanie sa používa na identifikáciu komunít alebo skupín v rámci sociálnych sietí, čo môže pomôcť pochopiť sociálne správanie, vplyv a trendy.
- Kyber ochrana: Klastrovanie sa používa na zoskupovanie podobných vzorcov sieťovej prevádzky alebo správania systému, čo môže pomôcť pri odhaľovaní a prevencii kybernetických útokov.
- Klimatická analýza: Klastrovanie sa používa na zoskupovanie podobných vzorcov klimatických údajov, ako sú teplota, zrážky a vietor, čo môže pomôcť pochopiť zmenu klímy a jej vplyv na životné prostredie.
- Športová analýza: Klastrovanie sa používa na zoskupovanie podobných vzorcov údajov o výkonnosti hráčov alebo tímu, čo môže pomôcť pri analýze silných a slabých stránok hráča alebo tímu a pri prijímaní strategických rozhodnutí.
- Analýza kriminality: Klastrovanie sa používa na zoskupovanie podobných vzorcov údajov o trestnej činnosti, ako je poloha, čas a typ, čo môže pomôcť pri identifikácii ohniskov kriminality, predpovedaní budúcich trendov kriminality a zlepšovaní stratégií prevencie kriminality.
Záver
V tomto článku sme diskutovali o klastrovaní, jeho typoch a aplikáciách v reálnom svete. V učení bez dozoru je potrebné pokryť oveľa viac a klastrová analýza je len prvým krokom. Tento článok vám môže pomôcť začať s klastrovacími algoritmami a pomôcť vám získať nový projekt, ktorý možno pridať do vášho portfólia.
Často kladené otázky (FAQ) o klastrovaní
Otázka: Aká je najlepšia metóda klastrovania?
Top 10 klastrovacích algoritmov je:
rozdiel medzi levom a tigrom
- K-znamená klastrovanie
- Hierarchické klastrovanie
- DBSCAN (Density-Based Space Clustering of Applications with Noise)
- Gaussovské modely zmesi (GMM)
- Aglomeratívne klastrovanie
- Spektrálne zhlukovanie
- Klastrovanie priemerných posunov
- Propagácia afinity
- OPTIKA (poradové body na identifikáciu zhlukovacej štruktúry)
- Birch (vyvážené iteratívne znižovanie a zoskupovanie pomocou hierarchií)
Otázka: Aký je rozdiel medzi zoskupovaním a klasifikáciou?
Hlavný rozdiel medzi zhlukovaním a klasifikáciou je v tom, že klasifikácia je algoritmus učenia pod dohľadom a zhlukovanie je algoritmus učenia bez dozoru. To znamená, že klastrovanie aplikujeme na tie množiny údajov, ktoré nemajú cieľovú premennú.
Otázka: Aké sú výhody zhlukovej analýzy?
Údaje je možné organizovať do zmysluplných skupín pomocou silného analytického nástroja zhlukovej analýzy. Môžete ho použiť na presné určenie segmentov, nájdenie skrytých vzorcov a zlepšenie rozhodnutí.
Q. Ktorá je najrýchlejšia metóda klastrovania?
Klastrovanie K-means sa často považuje za najrýchlejšiu metódu zhlukovania vďaka svojej jednoduchosti a výpočtovej účinnosti. Iteratívne priraďuje dátové body najbližšiemu ťažisku klastra, vďaka čomu je vhodný pre veľké množiny údajov s nízkou dimenzionálnosťou a miernym počtom klastrov.
Otázka: Aké sú obmedzenia klastrovania?
Obmedzenia klastrovania zahŕňajú citlivosť na počiatočné podmienky, závislosť od výberu parametrov, ťažkosti pri určovaní optimálneho počtu klastrov a problémy so spracovaním vysokorozmerných alebo zašumených údajov.
Q. Od čoho závisí kvalita výsledku klastrovania?
Kvalita výsledkov klastrovania závisí od faktorov, ako je výber algoritmu, metrika vzdialenosti, počet klastrov, metóda inicializácie, techniky predbežného spracovania údajov, metriky hodnotenia klastrov a znalosti domény. Tieto prvky spoločne ovplyvňujú účinnosť a presnosť výsledku zoskupovania.