V tomto článku budeme diskutovať o algoritme BFS v dátovej štruktúre. Vyhľadávanie do šírky je algoritmus prechodu grafu, ktorý začína prechádzať grafom od koreňového uzla a skúma všetky susedné uzly. Potom vyberie najbližší uzol a preskúma všetky nepreskúmané uzly. Pri použití BFS na prechod možno za koreňový uzol považovať ktorýkoľvek uzol v grafe.
Existuje mnoho spôsobov, ako prechádzať grafom, ale spomedzi nich je BFS najbežnejšie používaným prístupom. Je to rekurzívny algoritmus na vyhľadávanie všetkých vrcholov stromovej alebo grafovej dátovej štruktúry. BFS rozdeľuje každý vrchol grafu do dvoch kategórií – navštívené a nenavštívené. Vyberie jeden uzol v grafe a potom navštívi všetky uzly susediace s vybraným uzlom.
Aplikácie algoritmu BFS
Aplikácie algoritmu do šírky sú uvedené nasledovne -
- BFS možno použiť na nájdenie susedných miest z daného zdroja.
- V sieti typu peer-to-peer je možné použiť algoritmus BFS ako metódu prechodu na nájdenie všetkých susedných uzlov. Väčšina klientov torrentu, ako sú BitTorrent, uTorrent atď., využíva tento proces na nájdenie „semien“ a „rovesníkov“ v sieti.
- BFS možno použiť vo webových prehľadávačoch na vytváranie indexov webových stránok. Je to jeden z hlavných algoritmov, ktoré možno použiť na indexovanie webových stránok. Začne sa prechádzať zo zdrojovej stránky a nasleduje odkazy spojené so stránkou. Tu sa každá webová stránka považuje za uzol v grafe.
- BFS sa používa na určenie najkratšej cesty a minimálneho kostry.
- BFS sa používa aj v Cheneyho technike na duplikovanie zberu odpadu.
- Môže sa použiť vo ford-Fulkersonovej metóde na výpočet maximálneho prietoku v prietokovej sieti.
Algoritmus
Kroky zahrnuté v algoritme BFS na preskúmanie grafu sú uvedené takto -
Krok 1: SET STATUS = 1 (stav pripravenosti) pre každý uzol v G
disketa
Krok 2: Zaraďte počiatočný uzol A a nastavte jeho STAV = 2 (čakajúci stav)
Krok 3: Opakujte kroky 4 a 5, kým nebude QUEUE prázdny
Krok 4: Dequeue uzol N. Spracujte ho a nastavte jeho STATUS = 3 (stav spracovania).
Krok 5: Zaraďte všetkých susedov N, ktorí sú v stave pripravenosti (ktorých STATUS = 1) a nastavte
ich STAV = 2
ak inak, ak java
(stav čakania)
[KONIEC SLUČKY]
Krok 6: VÝCHOD
Príklad algoritmu BFS
Teraz pochopme fungovanie algoritmu BFS pomocou príkladu. V nižšie uvedenom príklade je orientovaný graf so 7 vrcholmi.
bublinové triedenie v algoritme
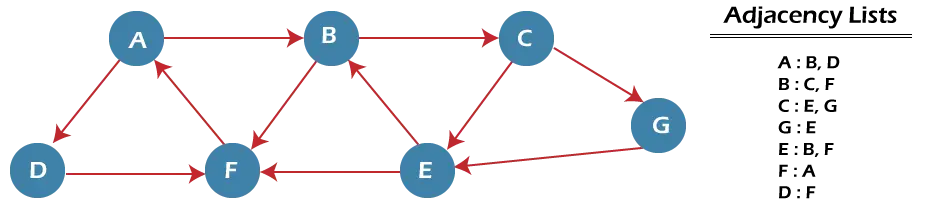
Vo vyššie uvedenom grafe možno nájsť minimálnu cestu 'P' pomocou BFS, ktorá začína od uzla A a končí v uzle E. Algoritmus používa dva fronty, menovite QUEUE1 a QUEUE2. QUEUE1 obsahuje všetky uzly, ktoré sa majú spracovať, zatiaľ čo QUEUE2 obsahuje všetky uzly, ktoré sú spracované a odstránené z QUEUE1.
Teraz začnime skúmať graf od uzla A.
Krok 1 - Najprv pridajte A do queue1 a NULL do queue2.
QUEUE1 = {A} QUEUE2 = {NULL} Krok 2 - Teraz odstráňte uzol A z frontu1 a pridajte ho do frontu2. Vložte všetkých susedov uzla A do frontu1.
QUEUE1 = {B, D} QUEUE2 = {A} Krok 3 - Teraz odstráňte uzol B z frontu1 a pridajte ho do frontu2. Vložte všetkých susedov uzla B do frontu1.
príklady java kódu
QUEUE1 = {D, C, F} QUEUE2 = {A, B} Krok 4 - Teraz odstráňte uzol D z frontu1 a pridajte ho do frontu2. Vložte všetkých susedov uzla D do frontu1. Jediným susedom uzla D je F, pretože je už vložený, takže sa znova nevloží.
QUEUE1 = {C, F} QUEUE2 = {A, B, D} Krok 5 - Vymažte uzol C z frontu1 a pridajte ho do frontu2. Vložte všetkých susedov uzla C do fronty1.
konverzia typu java a pretypovanie
QUEUE1 = {F, E, G} QUEUE2 = {A, B, D, C} Krok 5 - Vymažte uzol F z frontu1 a pridajte ho do frontu2. Vložte všetkých susedov uzla F do fronty1. Keďže sú už prítomní všetci susedia uzla F, nevložíme ich znova.
QUEUE1 = {E, G} QUEUE2 = {A, B, D, C, F} Krok 6 - Odstrániť uzol E z fronty1. Keďže všetci jeho susedia už boli pridaní, nebudeme ich znova vkladať. Teraz sú navštívené všetky uzly a cieľový uzol E sa nachádza vo fronte2.
QUEUE1 = {G} QUEUE2 = {A, B, D, C, F, E} Zložitosť algoritmu BFS
Časová zložitosť BFS závisí od dátovej štruktúry použitej na reprezentáciu grafu. Časová zložitosť algoritmu BFS je O(V+E) , pretože v najhoršom prípade algoritmus BFS skúma každý uzol a hranu. V grafe je počet vrcholov O(V), zatiaľ čo počet hrán je O(E).
Priestorová zložitosť BFS môže byť vyjadrená ako O(V) , kde V je počet vrcholov.
Implementácia BFS algoritmu
Teraz sa pozrime na implementáciu algoritmu BFS v jazyku Java.
V tomto kóde používame zoznam susedstiev na znázornenie nášho grafu. Implementácia algoritmu Breadth-First Search v jazyku Java výrazne zjednodušuje prácu so zoznamom susedných miest, pretože musíme prejsť zoznamom uzlov pripojených ku každému uzlu, len čo je uzol vyradený z frontu (alebo začiatku) frontu.
V tomto príklade je graf, ktorý používame na demonštráciu kódu, uvedený takto -

import java.io.*; import java.util.*; public class BFSTraversal { private int vertex; /* total number number of vertices in the graph */ private LinkedList adj[]; /* adjacency list */ private Queue que; /* maintaining a queue */ BFSTraversal(int v) { vertex = v; adj = new LinkedList[vertex]; for (int i=0; i<v; i++) { adj[i]="new" linkedlist(); } que="new" void insertedge(int v,int w) adj[v].add(w); * adding an edge to the adjacency list (edges are bidirectional in this example) bfs(int n) boolean nodes[]="new" boolean[vertex]; initialize array for holding data int a="0;" nodes[n]="true;" que.add(n); root node is added top of queue while (que.size() !="0)" n="que.poll();" remove element system.out.print(n+' '); print (int i="0;" < adj[n].size(); iterate through linked and push all neighbors into if (!nodes[a]) only insert nodes they have not been explored already nodes[a]="true;" que.add(a); public static main(string args[]) bfstraversal graph="new" bfstraversal(10); graph.insertedge(0, 1); 2); 3); graph.insertedge(1, graph.insertedge(2, 4); graph.insertedge(3, 5); 6); graph.insertedge(4, 7); graph.insertedge(5, graph.insertedge(6, graph.insertedge(7, 8); system.out.println('breadth first traversal is:'); graph.bfs(2); pre> <p> <strong>Output</strong> </p> <img src="//techcodeview.com/img/ds-tutorial/64/bfs-algorithm-3.webp" alt="Breadth First Search Algorithm"> <h3>Conclusion</h3> <p>In this article, we have discussed the Breadth-first search technique along with its example, complexity, and implementation in java programming language. Here, we have also seen the real-life applications of BFS that show it the important data structure algorithm.</p> <p>So, that's all about the article. Hope, it will be helpful and informative to you.</p> <hr></v;>